
Node.js Architecture - Single thread, call stack, synchronous and asynchronous I/O in Node.js
- Node.js Architecture - Introduction to Node.js
- Node.js Architecture - Single thread, call stack, synchronous and asynchronous I/O in Node.js 👈
- Node.js Architecture - How does Node.js handle asynchronous tasks?
- Node.js Architecture - The Event Loop
- process.nextTick, setImmediate, and setTimeout
Problem
C is a programming language known to many when starting a career. C is simple to approach but can become a "nightmare" for those who want to delve deeper into it. Programming is similar to explaining something to someone else, except here you are explaining it to a computer. Creating a program involves interpreting what you want to do step-by-step, line-by-line. Then the computer executes the program in the written order. That means the code runs sequentially from top to bottom, left to right, processing one block before moving to the next.
For example, a program that prints the words Hello World two seconds apart in C:
#include <stdio.h>
#include <unistd.h>
int main() {
printf("Hello");
sleep(2);
printf("World");
return 0;
}
At first glance, anyone can guess that the code above prints Hello first, then pauses for 2 seconds before printing World. Code that runs this way is called synchronous code.
However, in JavaScript/Node.js, you need to get accustomed to the concept of asynchronous behavior. Some functions are designed to run synchronously, while others are asynchronous to optimize performance. Asynchronous means the code does not return results immediately but at some point in the future.
Look at the following example and guess what the final result is:
setTimeout(function() {
console.log("Hello");
}, 0);
console.log("World");
The code above prints World Hello instead of Hello World, even though the line console.log("Hello") is written first. This is because setTimeout is an asynchronous function, and its result is not immediately available, so the code continues to run, printing World first.
Why does JavaScript/Node.js need to be asynchronous? To understand the reason, you first need to know how it works.
Single Thread
You may have heard a lot about JavaScript/Node.js being single-threaded. This means the code is executed in a single thread. If that's the case, how can it handle thousands of requests simultaneously with just one thread? Imagine an API server with an endpoint that takes 5 seconds to return a result, while many requests are being sent simultaneously. Since Node.js has only one thread, does it mean subsequent requests have to wait for the previous ones to complete before being processed? If so, wouldn't it be terrible compared to other server-side languages?
Fortunately, this doesn't happen because JavaScript/Node.js is equipped with an asynchronous processing mechanism. In Node.js, there are both synchronous and asynchronous functions. Basic statements like variable declarations, arithmetic operations +-x:, if else, switch case, loops, JSON.parse, and Node.js functions that end with the suffix sync, like readFileSync, gzipSync... are executed synchronously. Most other functions, designed to be asynchronous, like readFile, gzip... or HTTP requests, aim not to block the event loop.
Call Stack
The call stack is the execution stack for JavaScript commands. For code to execute, it needs to be pushed into the call stack. Since it is a stack, it follows the Last In First Out (LIFO) principle. The call stack ensures the program's execution order.
To clarify how the call stack works, look at the following example of code that converts Celsius to Fahrenheit:
const add = (a, b) => a + b;
const multiply = (a, b) => a * b;
const addCofficient = (val) => multiply(val, 1.8);
const addConst = (val) => add(val, 32);
const convertCtoF = (val) => {
let result = val;
result = addCofficient(result);
result = addConst(result);
return result;
};
convertCtoF(100);
In the example above, the function convertCtoF is eventually called. convertCtoF calls two functions: addCofficient and addConst. The call stack ensures the program's execution order by arranging the called functions in a stack.
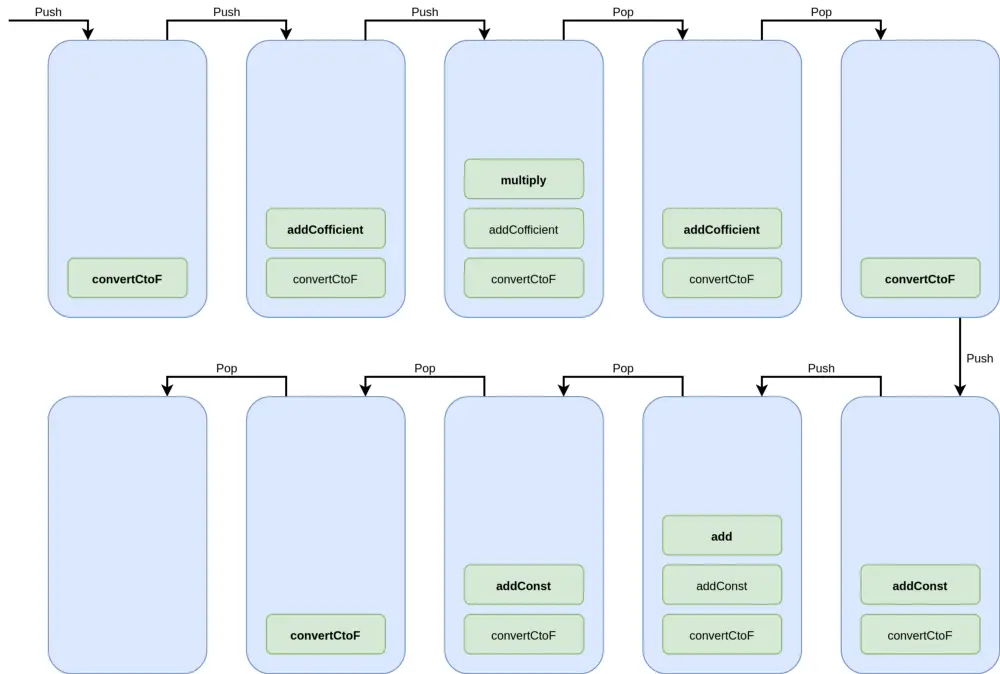
We can see that convertCtoF is pushed onto the call stack first, followed by the function addCofficient. Inside addCofficient, it calls the function multiply, which is then pushed on top of the stack. When there are no more functions inside, the call stack starts executing the program. The call stack also plays an important role in determining the location of errors. If an error occurs, the error message displays the Error Stack Trace, i.e., the location of the error. Since functions are pushed onto the call stack in order, the error trace can easily pinpoint their location in the program.
Let's modify the addConst function by replacing the second parameter in the add function with an undefined variable.
const addConst = (val) => add(val, number);
Running the program triggers an error, including the cause and location of the error.
ReferenceError: number is not defined
at addConst:5:32
at convertCtoF:10:12
at eval:14:1
This message means that number is not defined, at line 5, starting at column 32, inside the convertCtoF function at line 10, starting at column 12...
What happens if a function that takes a long time to process is pushed into the call stack? Suppose addConst takes 5 seconds to execute; it occupies 5 seconds of the call stack before being released. This is why we need asynchronous functions. So how does the call stack handle asynchronous functions? To understand this, we first need to learn about I/O.
I/O Operations
I/O tasks involve reading/writing data, files, or network-related tasks like HTTP requests, sockets, etc. I/O appears everywhere in server-side programming. Simply put, database queries can also be considered I/O tasks.
In Node.js, I/O consists of two types: synchronous and asynchronous.
Synchronous I/O
Consider the following example of reading file contents:
const pdf = fs.readFileSync(file.pdf);
console.log("pdf size", pdf.size);
const doc = fs.readFileSync(file.doc);
console.log("doc size", doc.size);
Remember, functions ending with sync are usually synchronous. Reading a file is an I/O task that takes considerable time to process. readFileSync is a synchronous function; file.pdf is read first, then file.doc. The processing time for the two functions is illustrated below.

The time to read file.pdf is 3ms, and file.doc is 3ms. Printing the results takes 2ms, so the total time we have to wait for all tasks to complete is 6ms.
6ms is very fast. But imagine the file sizes increase, leading to longer reading times. What happens then? Most likely, the call stack won't be able to execute additional code, and the program will run sequentially: read -> print -> read -> print...
Asynchronous I/O
Now let's modify the above code slightly by replacing the readFileSync function with readFile:
const pdf = fs.readFile(file.pdf);
console.log("pdf size", pdf.size);
const doc = fs.readFile(file.doc);
console.log("doc size", doc.size);
readFile is an asynchronous function. An asynchronous function does not return results immediately but at some point in the future. If you run the above code, you might see results like this:
pdf size undefined
doc size undefined
This is because the file reading results are not immediately available, so any attempt to access the size property yields no results. The results of asynchronous functions are usually returned through a callback function. From ES6 onwards, we also have the concept of Promise, where asynchronous function results are returned in the then block of the Promise.
fs.readFile(file.pdf)
.then(pdf => console.log("pdf size", pdf.size));
fs.readFile(file.doc)
.then(doc => console.log("doc size", doc.size));
then is used to receive results, similar to the callback of asynchronous functions. If you don't use then, you can use a callback function to receive results like this:
fs.readFile(file.pdf, function(err, pdf) {
console.log("pdf size", pdf.size);
})
Processing time is significantly reduced when replacing the readFileSync function with readFile, as shown in the diagram below.

Conclusion
Node.js, with its single-threaded architecture combined with an asynchronous mechanism, effectively solves the concurrency problem without causing bottlenecks—a major challenge for traditional server systems. The call stack ensures code execution order based on the Last In First Out (LIFO) principle. The difference between synchronous and asynchronous I/O is also clarified: while synchronous I/O blocks the entire process until the task is completed, asynchronous I/O allows the program to continue executing, significantly reducing wait times and increasing the ability to handle large requests.
In the next article, let's explore how JavaScript/Node.js handles asynchronous operations.