
What is Redisearch? 2coffee.dev is using redisearch as the database!
Issue
Databases are an essential part of modern websites. Most of us have heard of two main types: SQL and NoSQL. Each has its own strengths and weaknesses, depending on the use case. Redis is a NoSQL database that is commonly used for data caching purposes.
For those who don't know, my blog uses redisearch as the database. Redisearch is a module of Redis. Before adopting redisearch, I used MySQL. But why? Is it difficult to switch to redisearch and is it easy to use redisearch? Let’s explore these questions in this article...
What is Redisearch?
Redisearch is a module of Redis that provides powerful full-text search capabilities, indexing, and querying. You know the LIKE command in SQL, right? It is used to search for data that matches a specified pattern. However, LIKE has limitations in SQL, such as slow search speed on large datasets and difficulty in performing complex searches like spelling errors or phrase suggestions. Redisearch overcomes these limitations.
Redisearch uses inverted indexes along with compression, allowing for fast indexing with low memory costs. "Inverted indexes" are a type of index that stores an mapping from content, such as words or numbers, to its position in a table or document or a set of documents. Its purpose is to allow fast "full-text" searches. Their "compressed" technology is used to reduce storage costs.
If you have experience using Redis for data caching, then you will find that Redisearch offers both speed and powerful querying capabilities.
Why did I choose Redisearch?
The nature of a blog is that reading data is more common than writing, so I always prioritize retrieving data as quickly and accurately as possible. Moreover, with a modest server configuration of 1 CPU and 1GB RAM, memory optimization and processing speed for the system are crucial.
As mentioned earlier, I used MySQL before. In terms of stability, MySQL is very stable and has good data querying capabilities. However, it consumes a relatively large amount of memory, and its full-text search capabilities were not strong enough for my requirement of search being the main feature of the blog.
I've heard about Redisearch for a long time but never had the opportunity to explore it. Coincidentally, while searching for a solution to the above problem, I decided to dive into researching whether I could apply it to my project. As expected, Redisearch fully met my expectations.
Initially, I only intended to use Redisearch as a secondary database for full-text search, but later I discovered that Redisearch can handle both storage and data retrieval capabilities, making it a complete replacement for MySQL.
Redisearch is currently in the process of being improved to receive more from the community. As a result, there were many difficulties when transitioning from MySQL to Redisearch initially. However, the documentation on the Redisearch homepage is quite comprehensive, so most of the issues I encountered were resolved.
How to use Redisearch?
Installing Redisearch
The first thing you need to do is install Redisearch. There are several ways to install Redisearch, such as using Docker, installation packages, or building from source.
To install with Docker, use the following command:
docker run -p 6379:6379 redislabs/redisearch:latest
Or you can see all other ways in the Quick Start Guide for RediSearch.
Creating an index
We need to create an index before using it for searching. The index is responsible for indexing and searching.
Use the FT.CREATE command to create an index.
For example, I create an index named article to store articles:
FT.CREATE article ON HASH PREFIX 1 article: SCHEMA url TAG SEPARATOR "," title TEXT content WEIGHT 5.0 TEXT created_at NUMERIC SORTABLE
The index article is stored in the HASH data type, with keys starting with article. It includes the following data fields: url with the TAG type, title and content with the TEXT data type, and created_at as NUMERIC to store the article creation date in Unix timestamp format.
Redisearch supports three data types for fields: TEXT, NUMERIC, and TAG. TAGs can be thought of as primary keys in SQL databases.
The WEIGHT parameter is used to determine the importance of a field. The higher the WEIGHT, the higher the priority in search results. SORTABLE needs to be declared if you want the data to be sorted during queries.
Adding data to the index
HSET article:1 url "hello-word" title "hello world" content "lorem ipsum" created_at 1630245601
HSET article:2 url "hello-word-2" title "hello world 2" content "lorem ipsum 2" created_at 1630245602
HSET article:3 url "hello-word-3" title "hello world 3" content "lorem ipsum 3" created_at 1630245603
Querying
Redisearch provides the ability to search based on data fields. You can perform exact searches, searches for specific words or phrases using logical operators like OR, AND, NOT in queries.
Check all the search query syntax that Redisearch supports in the Search Query Syntax.
To query based on a specific data field, use the @field syntax followed by the data to search for. For example:
Search by exact match on url:
FT.SEARCH article @url:{ hello-world }
Search for the phrase "hello world":
FT.SEARCH article @url:"hello world"
Search for articles with created_at greater than 1630245602:
FT.SEARCH article @created_at:[(1630245602 inf]
Retrieve all articles and sort them by created_at in descending order:
FT.SEARCH article * SORTBY created_at DESC
Data stored in Redisearch is analyzed and processed according to certain rules. For example, special characters are ignored during indexing unless we intervene. To understand these rules in more detail, see Controlling Text Tokenization and Escaping.
Speed
In terms of indexing and search speed, Redisearch is not inferior to any other search tool such as Elastic Search or Solr. In fact, it has an amazing search speed.
In a specific case, the developers on the Redis blog performed a performance comparison between Redisearch and Elastic Search by indexing and searching 5.6 million documents taken from the Wikipedia website.
Indexing results: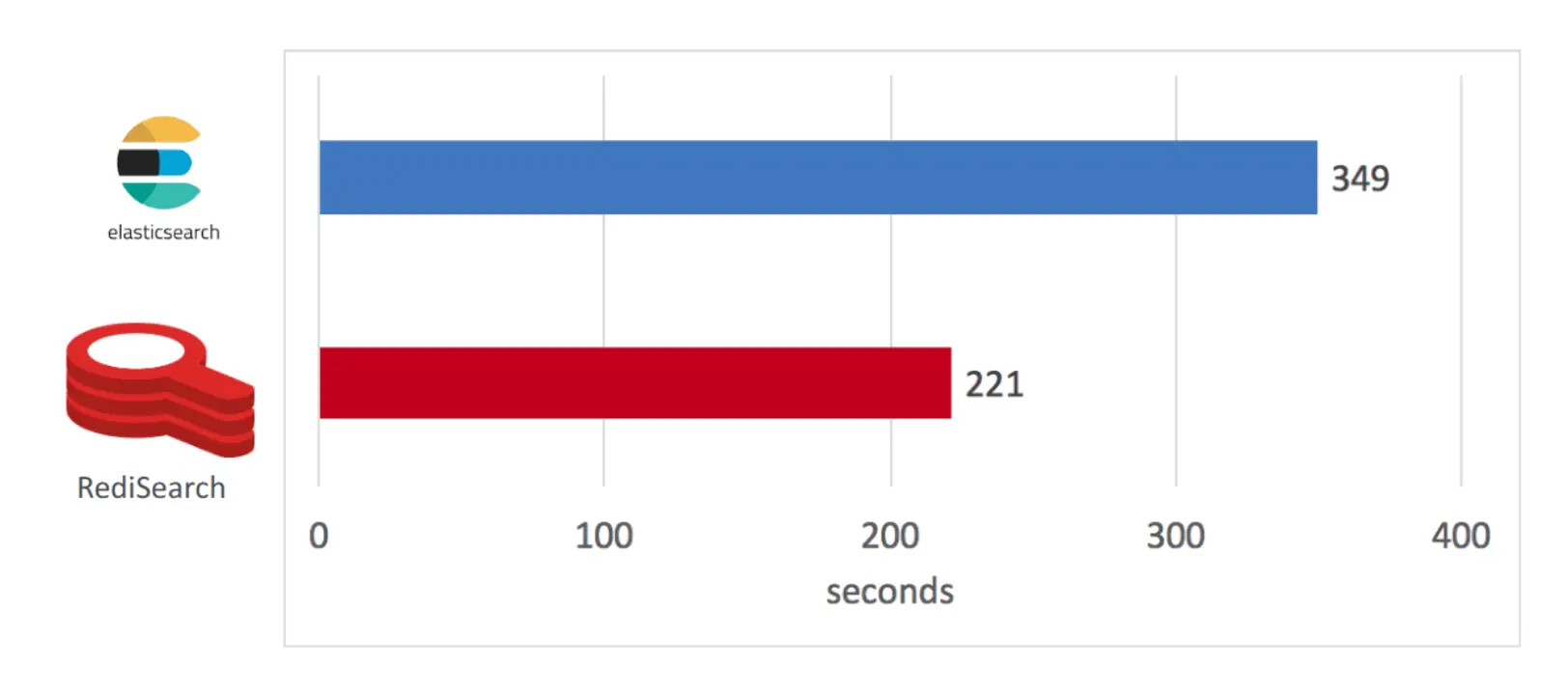
Search results with two random keywords: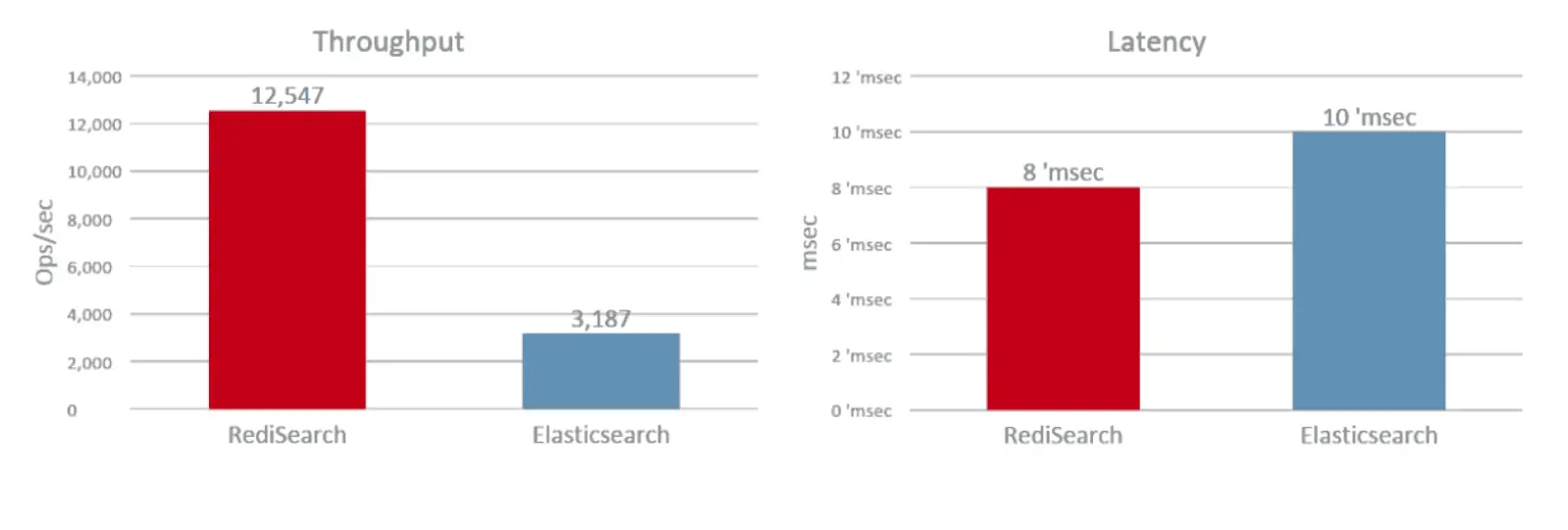
For more details, you can read Search Benchmarking: RediSearch vs. Elasticsearch.
Summary
Redisearch is a powerful database that supports indexing and full-text search with optimized memory costs. I came across Redisearch while looking for a full-text search solution to replace Elastic Search, which requires relatively high server configurations.
Redisearch supports multiple search syntaxes on multiple data fields within an index. In addition, you can assign weights to documents to improve search accuracy, and search results are evaluated based on search scores.
In terms of performance, Redisearch is not inferior to any other search tools such as Elastic Search or Solr.