
Using GPT-4 for Free Through Github Models (with Limitations)
The Issue
As a social media user, it is not difficult to see posts asking if anyone wants to share a ChatGPT Plus account. By subscribing to the Plus version, you can use the latest and most powerful models, such as gpt-4, gpt-4o, or o1-preview... This shows that the demand for using these models is very high. Many users do so for research and study purposes. Or simply to experience something new, to see what is outstanding compared to what is already known.
With a price of $20 a month, I am sure many people will hesitate. We have too many bills to pay in a month, and there are many more important things to spend on. Therefore, if someone is willing to "chip in" to share the costs, it would be great; the cost would be reduced exponentially. If five people share, each person only needs to pay $4. However, this also creates many new problems. Currently, ChatGPT limits the number of queries within a certain time frame. Therefore, if someone "accidentally" uses up all the queries, the next user must wait until the limit resets. Not to mention the financial risks of sharing with strangers. Thus, it is best to only share with people you know.
Previously, I wrote an article about how to use GPT-4 for free through Github Copilot. But in the end, this was just an unofficial "trick," and I warned readers that there was a risk of their Copilot accounts being "flagged." As of now, it is uncertain whether this method still works, but readers should not follow it anymore. According to statistics, that article still has many readers. Wow! The allure of GPT-4 is remarkable!
On the occasion that Github just public previewed Github Models for anyone with a Github account to access their models, including many models of GPT and other well-known models like Llama, Mistral... In this article, I will guide everyone on how to use GPT-4 for free in a way that is as similar to ChatGPT as possible. And of course, it is not as good as the official version, with many limitations included, but it is still worth experiencing.
Github Models
Github Models is a feature that Github supports developers to use large language models (LLMs) for free for testing purposes - as they say. After completing the testing phase, users must deploy their applications with other providers because the testing models have many limitations in speed and context. However, if only used for personal purposes, it is acceptable.
We all know the website ChatGPT is for everyone - especially free users - to chat with gpt-4o, 4o-mini... After a few exchanges, you will run out of queries and be "downgraded" to the gpt-3.5 model. ChatGPT saves the history of exchanges, allowing users to review past conversations. This is also the easiest way for users to interact with GPT models.
If you are not a developer, or perhaps are a developer but have not noticed, OpenAI - the company behind ChatGPT provides an API to interact with their models. Simply put, instead of using the web chat, you can completely call the API to do the same thing. For example, a conversation in the API would look like this:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
},
{
"role": "assistant",
"content": "Hi there! How can I assist you today?"
},
{
"role": "user",
"content": "What is the capital of Vietnam?"
}
]
}'
You will see that an API call includes all the content of the conversation. This means that to continue the conversation, you need to send back all the previous content between you and GPT. This explains that it is the context of the conversation. GPT does not store state, so the best way to help it understand the content being discussed is to resend all previous content.
The special thing is that by calling the API, you can use the latest models without necessarily subscribing to the $20 GPT Plus package. However, API calls cost money, and the billing is very different from the web version. You pay more if you call the API more often, and the length of the conversation also incurs more costs since the API charges based on input/output tokens. Not to mention, the input/output costs differ depending on the model you use.
"Wow, this is really confusing. Just calculating the costs is already so complicated that it might be easier to just subscribe to Plus 😆." Surely many people will think like that after reading this, but it's true! You spend money to buy satisfaction; that is the pinnacle of sales art. If you spend a little time and get to use it for free, then it forces us to read and experiment more.
Below is the pricing table based on input/output tokens for the gpt-4o mini model.
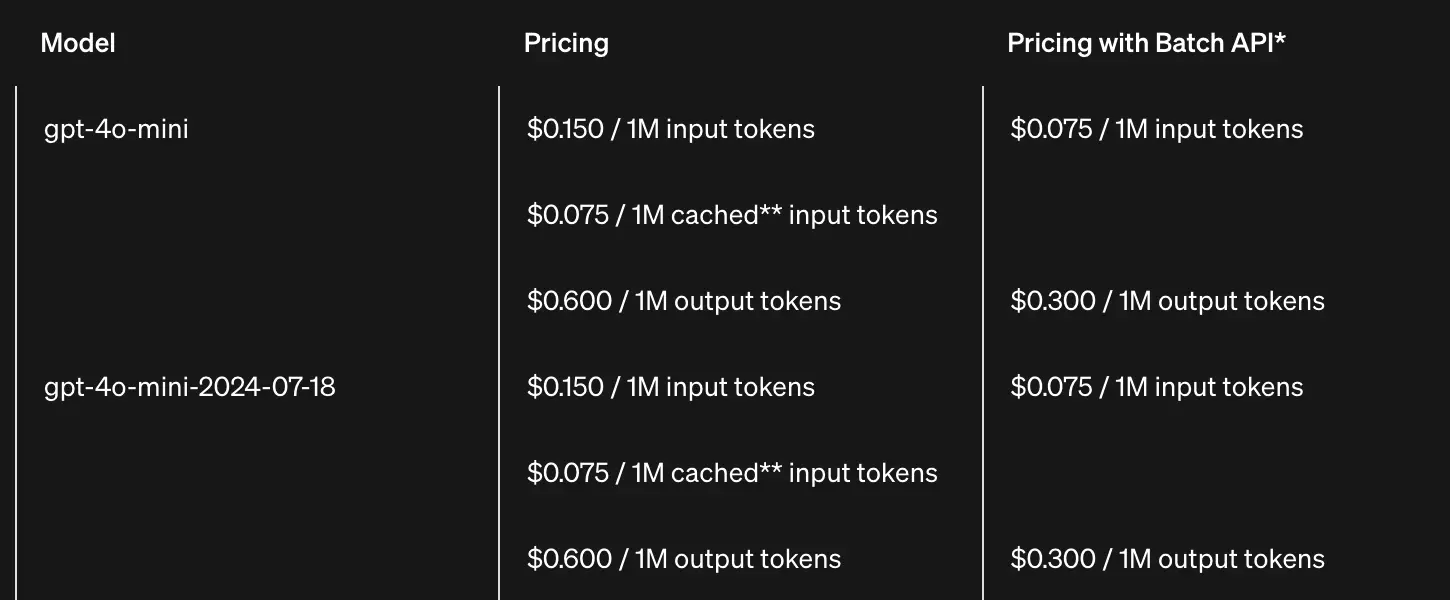
Input tokens are the number of characters sent, while Output tokens are the number of characters that the model responds with. This means that the more you send or the more the model responds, the more money you spend. Tokens are calculated based on a few principles; basically, you can think of them as roughly equivalent to words (1 token = 3/4 word), meaning 3 words will correspond to 3 tokens. A more standard formula can be found at Tokenizer | OpenAI Platform.
After registering an account on Github, access Marketplace Models and you will see a list of models available for use. Click on any model, for example, here is OpenAI GPT-4o mini. Click on the Playground button at the top right of the screen. Here you will see a chat interface very similar to ChatGPT. Try starting a conversation as usual. Congratulations, you are now using the gpt-4o mini for free.
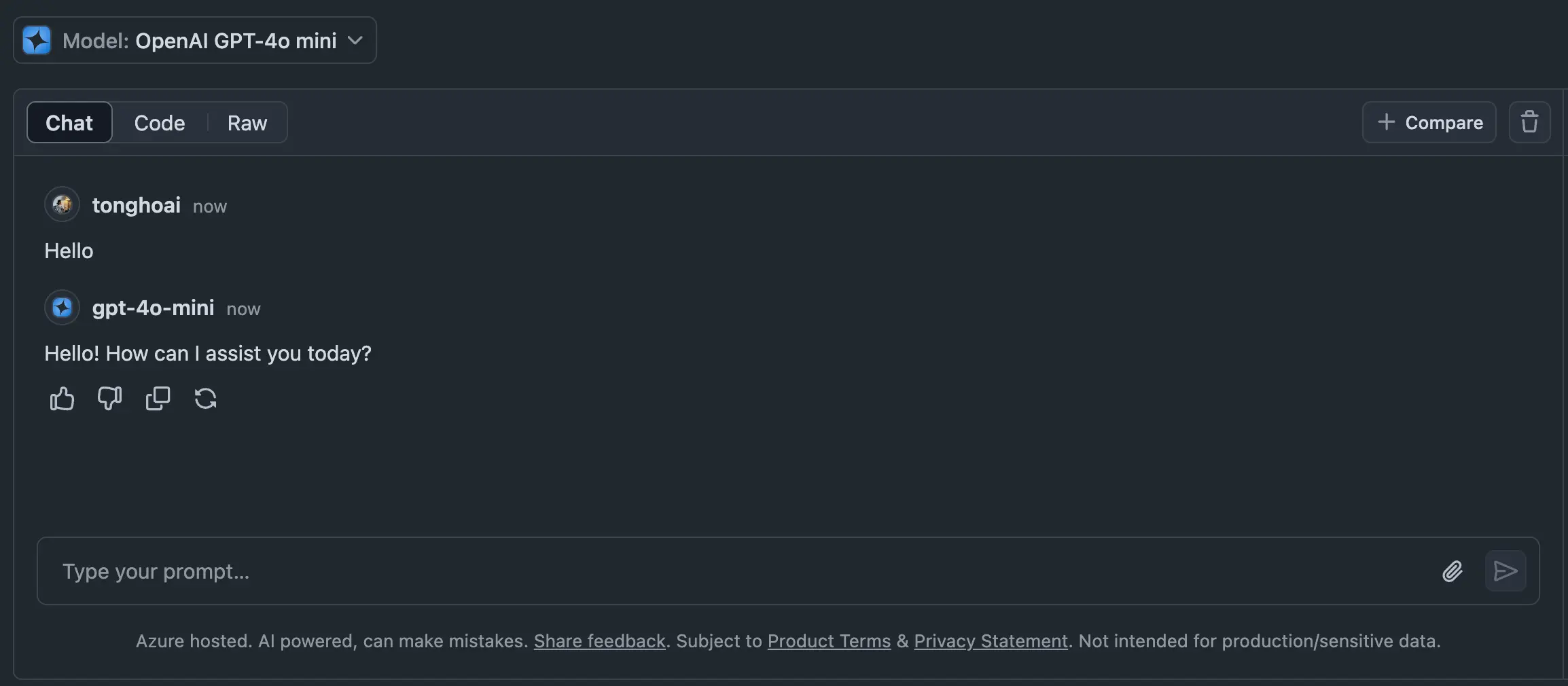
However, this method is a bit inconvenient as it does not save the conversation history, and the interface is not very user-friendly. Next, I will guide you through a much more "professional" way.
Lobe Chat
Lobe Chat is an open-source project that provides an interface and features to interact with large language models. Simply put, Lobe Chat provides a chat interface similar to ChatGPT.
Lobe Chat helps us manage conversations. In addition, it also tries to integrate many other features, but in the scope of this article, I will not mention them yet. Lobe Chat interacts with LLMs via API, so you need to configure the connection for calls to the corresponding model server. Here I will guide you to configure for Github Models.
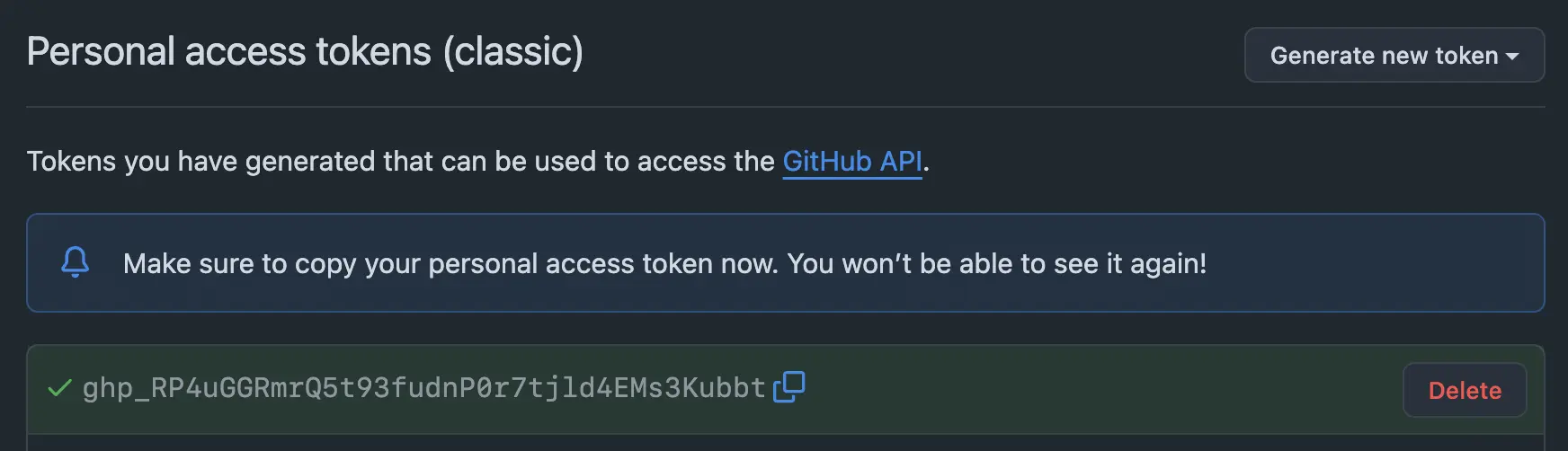
First, you need to obtain Github Tokens for basic authentication. Go to Personal access tokens | Github. Click on "Generate new token (classic)." Enter a name for the token and choose the expiration time for the token as you wish. You do not need to select any scopes. Click on Generate token at the bottom and save the token you just received.
Next, install Lobe Chat on your computer. You can deploy Lobe Chat to many cloud services like Vercel, Zeabur... with just one click because Lobe is a web-based application. Or if using Docker, simply run one command.
$ docker run -d -p 3210:3210 --name lobe-chat lobehub/lobe-chat
Access http://localhost:3210 to see the interface of Lobe Chat. Next, we need to set up the API configuration for it to work.
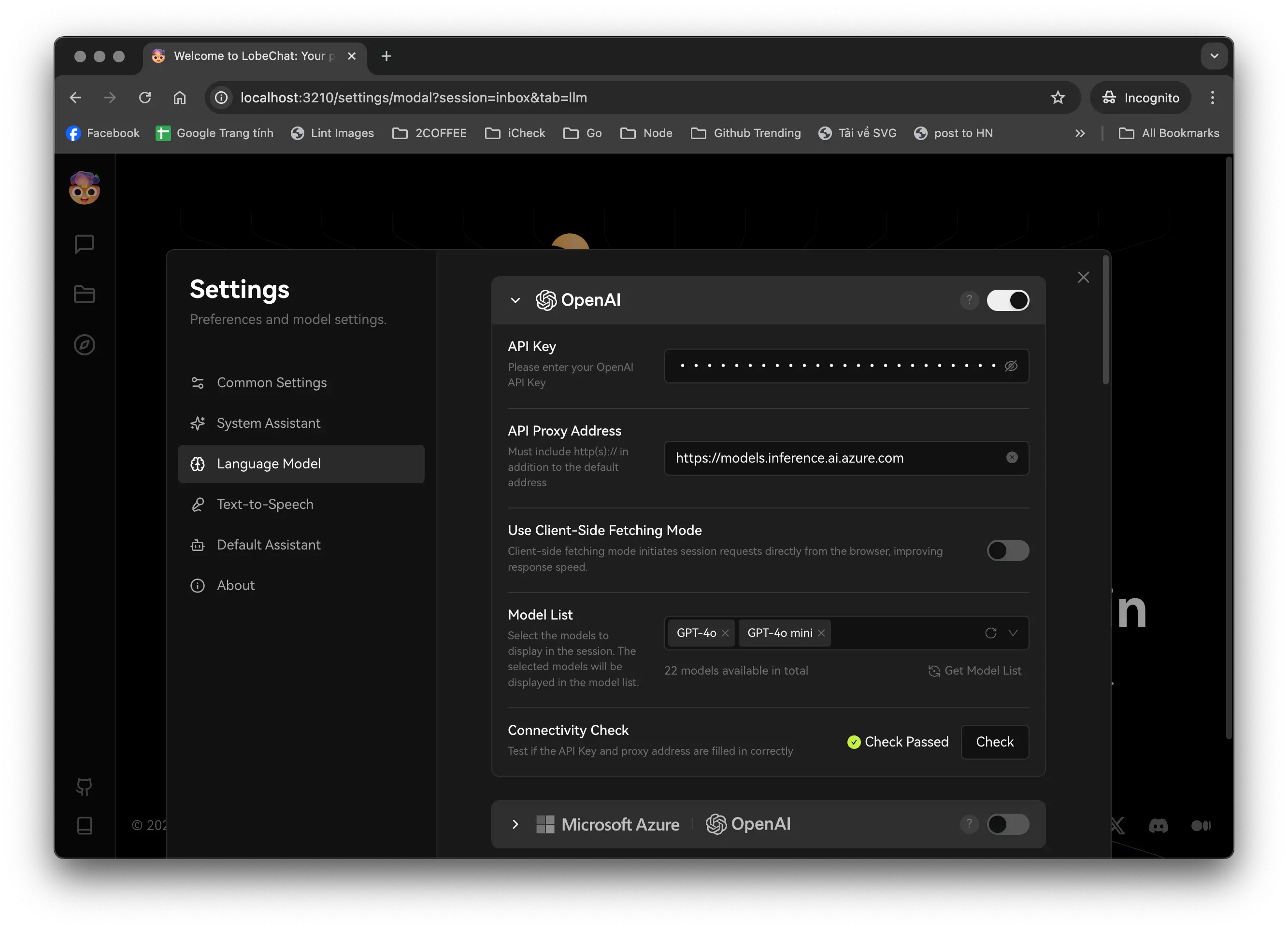
Click on the Lobe Chat avatar at the top left, select "Settings," click on the "Language Model" tab, and you will see the OpenAI setup screen. You need to fill in "API Key," "API Proxy Address," and "Model List." The API Key is the Github token you just created above, and the API Proxy Address at the time of writing this article is:
https://models.inference.ai.azure.com
In the "Model List" box, enter the names of the models you want to use. To know the exact name of the model, visit each model on Github Models, click on Playground, and switch to the "Code" tab. For example, here I enter "gpt-4o," "gpt-4o-mini." Click on the "Check" button to verify if the configuration is correct. If "Check Passed" appears, it has been successful.
Now let's try to create a new conversation.
Wonderful!
Limitations
There are a few notable limitations that you need to be aware of while using it.
First is the limitation on chat speed and the number of API calls per day. Github labels each model to determine these limitations. For example, looking at the table below.
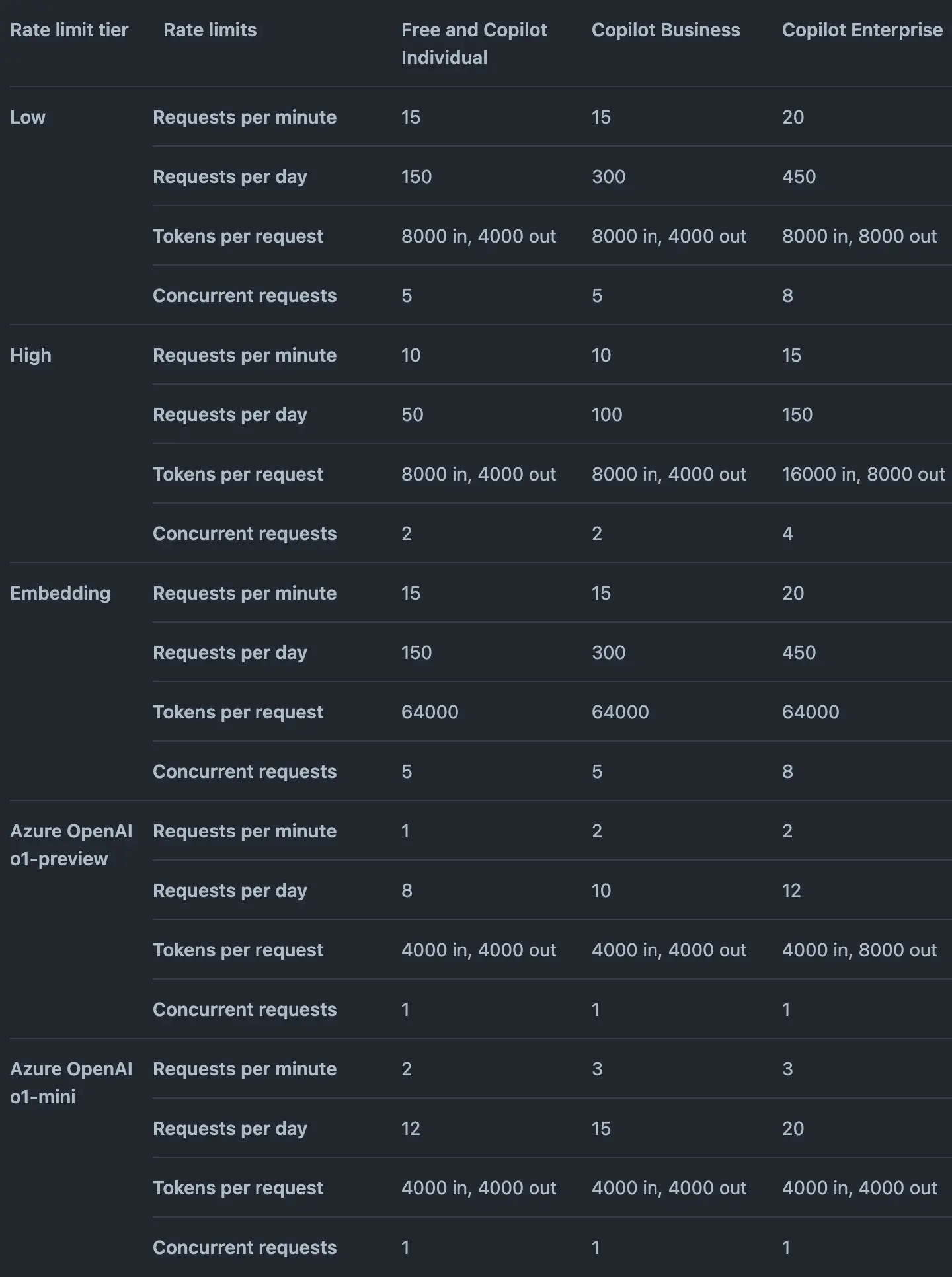
These labels are found in the details of the model. For example, for gpt-4o labeled "High," it means that in one day, you can only make 50 requests - equivalent to 50 questions, and you are limited to 10 requests per minute as well as a maximum of 2 requests concurrently.
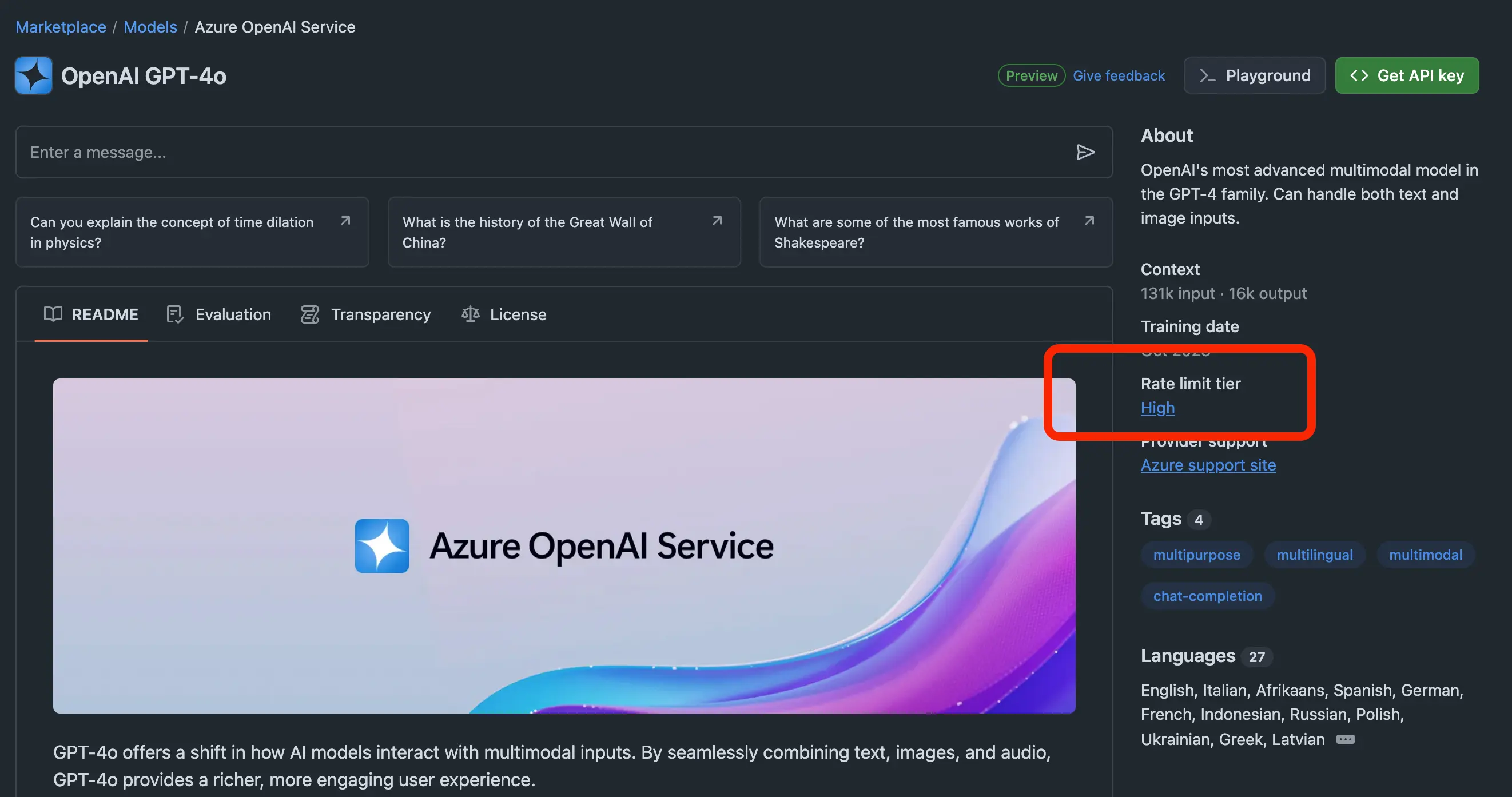
Additionally, pay attention to the "Tokens per request" which is the amount of tokens in/out for each request. For example, with gpt-4o it is "8000 in, 4000 out," meaning the maximum number of words sent is 8000 words, while the number of words that the model responds with is only a maximum of 4000. Meanwhile, gpt-4o supports input tokens up to 131k and output up to 16k. Clearly, there are too many limitations. Hopefully, in the future, Github will "expand" these limits.
You also cannot create images or audio. Lobe Chat only stores conversations on your computer, so you can only review the conversation created on your machine or switch to configuration on a cloud service.
Although there are still many limitations, for those who want to experience or use it infrequently, this is a "lifesaver" solution. If you exhaust the limits of this model, you can switch to another model to continue using. Besides GPT, there are still many powerful models waiting for you to explore.
Do you find this method interesting, or do you have any methods you want to share? Please leave your comments below the article. Thank you.