
Understanding Explicit Locking Types in PostgreSQL
The Problem
After working with SQL or PostgreSQL for a while, have you ever wondered what would happen if you executed a SELECT and DROP command on the same table at the same time? Which command would run first? What is the priority of these commands, and how does PostgreSQL determine it? In this article, I will explain how PostgreSQL uses Locks to handle data conflicts.
Why Do We Need Locks?
PostgreSQL provides various lock modes to control concurrent access to data in tables. These locks can be used to intervene in Multi Version Concurrency Control (MVCC) situations.
In addition, most PostgreSQL commands acquire appropriate locks to ensure that referenced tables are not deleted or modified in an unintended way while the commands are being executed. For example, the TRUNCATE command cannot be executed concurrently with other operations on the same table, such as SELECT... To make this happen, TRUNCATE is granted an ACCESS EXCLUSIVE lock.
Lock Modes
Postgres has the following lock modes:
- Table-Level Locks
- Row-Level Locks
- Page-Level Locks
- Advisory Locks
These lock modes describe the conflict domain of PostgreSQL commands at the table, row, or page level.
However, in this article, I will focus on two lock modes: Table and Row. You can learn more about other lock modes at the PostgreSQL documentation.
Table-Level Locks
These locks are table-level locks, and they are either granted automatically or by using the LOCK command.
Automatic means that depending on the SQL command being invoked, you are immediately granted the corresponding lock. Here are some common commands and their corresponding locks when they are invoked.
- SELECT: ACCESS SHARE
- UPDATE, DELETE, INSERT: ROW EXCLUSIVE
- CREATE INDEX: SHARE
- CREATE TRIGGER: SHARE ROW EXCLUSIVE
- DROP TABLE, TRUNCATE: ACCESS EXCLUSIVE
For more locks and details, refer to the PostgreSQL documentation.
The table below shows the conflict between locks.
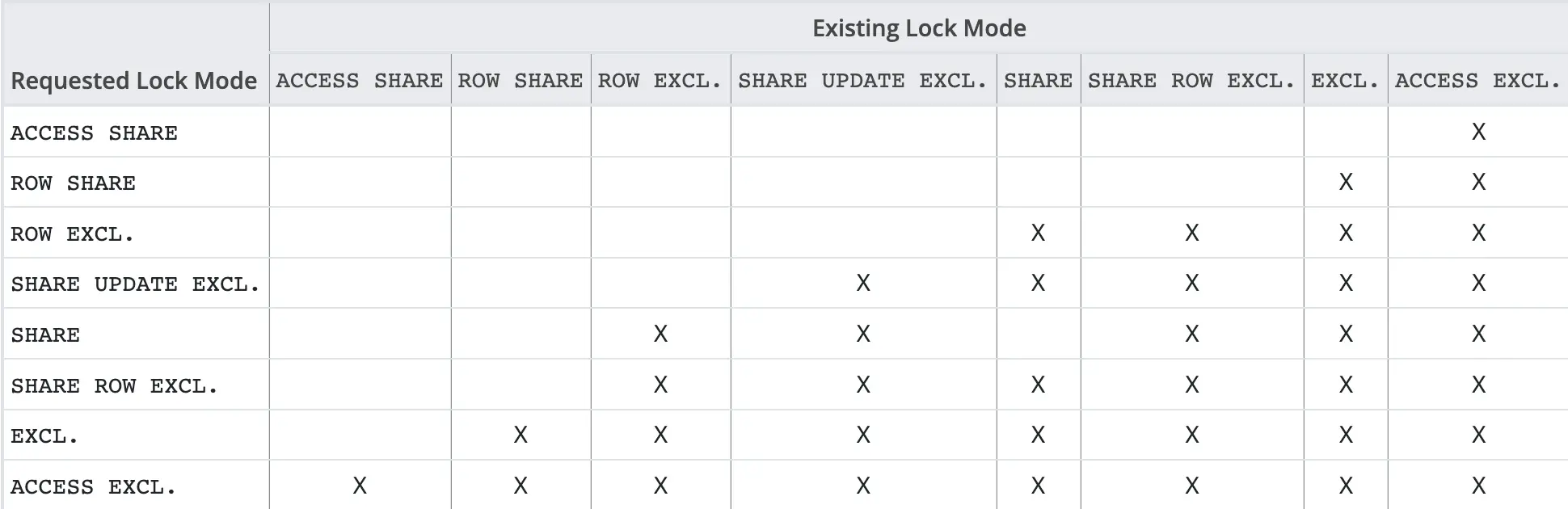
I can explain it as follows: looking at the table, we can see that the ACCESS SHARE lock conflicts with the ACCESS EXCLUSIVE lock. Therefore, in transactions, if a command is being executed first (holding the ACCESS SHARE lock), the subsequent command (holding the ACCESS EXCLUSIVE lock) has to wait until the transaction is completed, and vice versa.
-- (1)
BEGIN;
-- (2)
SELECT * FROM users; -- ACCESS SHARE LOCKS
-- (4)
COMMIT;
-- (3)
TRUNCATE users; -- ACCESS EXCLUSIVE LOCKS
Try running these commands on two separate processes following the steps (1) (2) (3) (4) to see what happens.
Row-Level Locks
Row-level locks are acquired by specifying the name of the lock in the query. There are 4 locks:
- FOR UPDATE
- FOR NO KEY UPDATE
- FOR SHARE
- FOR KEY SHARE
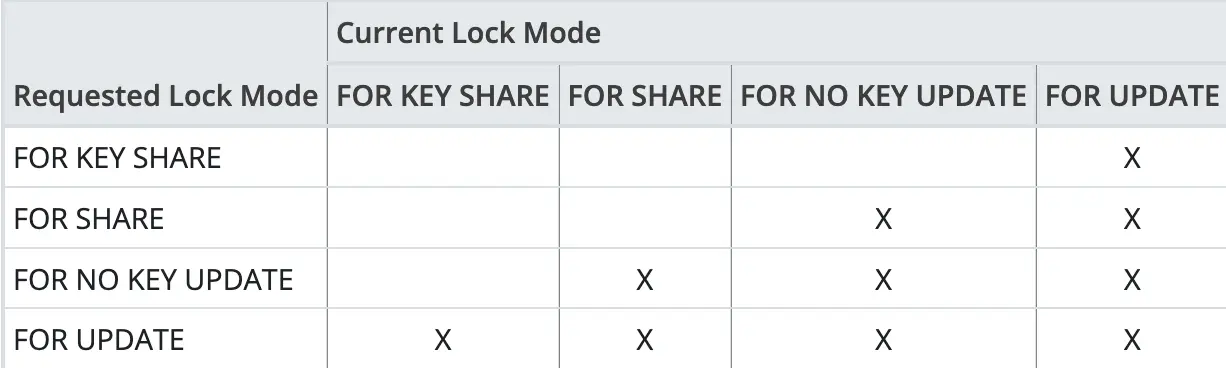
FOR UPDATE causes the rows retrieved by SELECT to be locked as if for an update. This prevents them from being locked, modified, or deleted by other transactions until the current transaction finishes. In other words, other transactions like DELETE or UPDATE on these rows will be blocked until the current transaction finishes.
Similar to Table-Level Locks, the table above describes the conflicts between locks. Conflicting locks have to wait until the preceding lock is released before they can proceed.
For example, you are developing a feature for gift exchange. There is a gift table that contains the remaining quantity of gifts you want to exchange, and a table that tracks the valid points you have for gift exchange. When exchanging a gift, you need to retrieve the remaining quantity and your points, perform multiple complex validations, and it takes a long time before you can proceed with the exchange. Assuming that in the first request, you retrieve the remaining quantity as 1, and in the second request immediately after, you also retrieve the remaining quantity as 1. What would happen if both requests continue with the gift exchange? To prevent this, you can use Row-Level Locks. This means that when one transaction is retrieving the remaining quantity to start validation, the second transaction has to wait until the first transaction finishes.
Deadlock
Deadlock occurs when two or more transactions hold locks that the other needs. For example, the first transaction acquires an ACCESS EXCLUSIVE lock on table A and then wants to acquire that lock on table B, while the second transaction already holds an ACCESS EXCLUSIVE lock on table B and now wants that lock on table A. In this case, no transaction can proceed. PostgreSQL automatically detects this situation and resolves it by aborting one of the related transactions, but it is unpredictable which transaction will be aborted.
Deadlock can also occur with row-level locks when transactions hold each other's locks.
The best defense against deadlocks in general is to avoid having commands acquire locks on multiple objects (tables/rows) in a specified order.
If a transaction operates on multiple related objects, it is best to keep the transaction duration as short as possible. Avoid holding transactions for long periods. For example, a bad practice is to execute a transaction and wait for user input.
Conclusion
In this article, I have presented how PostgreSQL uses locks to manage concurrent access to data in tables. Although specific to PostgreSQL, the concept of using locks still applies to other SQL databases such as MySQL and SQL Server. Understanding how locks work will help you handle situations in application development with SQL more effectively.