
Semantic Search Optimization
The Problem
RAG (Retrieval-Augmented Generation) is a method that combines information retrieval and text generation to improve the quality and accuracy of the answers generated by language models. The simplest way to understand RAG is to imagine chatting with ChatGPT; it almost answers all the questions you pose. The reason it has such profound knowledge is that it has been trained on many data sources. This is both an advantage and a disadvantage: the advantage is knowing everything; the disadvantage is that sometimes it doesn't know specifics and provides vague answers. RAG, however, does the opposite by limiting the amount of knowledge language models learn, only learning and answering questions based on a limited dataset we provide. It sounds simple, but the truth is much more complex.
RAG is gaining more attention because mastering this technology can bring many benefits. Among them is the ability to enhance the accuracy of answers. Training models based on our dataset and easily retrieving information back. It can be applied in many cases such as semantic search, explanations, intelligent answering, and content summarization on a defined dataset.
One of the most impressive examples of RAG I have encountered is NotebookLM. This tool helps us extract data based on what is provided, and it only answers based on the content given. For example, if you provide a link to any article, it will immediately summarize the content, suggest topics, and possible questions to extract from this article, or engage in direct conversation by asking any questions.
The semantic search feature I developed not long ago can also be considered a small application of RAG. It involves applying large language models, embedding models, summarization, converting content into vectors, storing them in a database, and querying. Finally, it returns articles related to what the user is searching for, a completely different approach from the previous full-text search.
After releasing for some time, I planned to monitor and analyze user behavior when they used the search function. I wanted to see if this new feature was helpful or if it worked as expected. I discovered some issues as follows.
Out of a total of 130 searches, there were 100 semantic searches and 30 full-text searches. When entering content and clicking search, the website prioritizes semantic search first. If there are no results or the user does not find satisfactory answers, they can click on "keyword search" to switch to the full-text search case. This means that less than 1/3 clicked on keyword search. Oh! Could it be that semantic search is good enough to make them not need to switch to keyword search anymore? There is a strong possibility that... No!
Delving into the content of user searches, I found that most users were trying to search using keywords. That is, they only entered very short words or phrases. For example, node.js, redis, jwt, module, commonjs... Such short keywords are mostly not found by semantic search because the input is too brief, not enough to query vectors for similarity, or causing noise. For keyword searches, full-text search yields better results.
I came to a conclusion: when users enter a short keyword, they might just want to find articles containing that keyword. Conversely, when they enter a longer question or keyword that contains context, they are more likely to have identified the issue clearly, at which point semantic search might be more appropriate.
Additionally, I noted some cases leaning towards semantic search, such as "node.js architecture," "fix commit not yet pushed"... Whenever I received such searches, I would often try to find out what results the users saw to plan for optimizing the search results.
Realizing that many results were not as expected, I spent the weekend reviewing this feature.
Optimizing Semantic Search
Before continuing, let me remind you a bit about the previous method!
First, I used LLMs to summarize the main content of the article. If the article has a length of 1,000 to 2,000 words, after summarization, the remaining content is only about 500 words. Then, I used the embedding model from nomic to convert it into vectors and stored it in the Supabase database for easy querying. At this point, the vectors have a size of 768, balancing meaning and search speed.
Summarizing the main content and "vectorizing" it is not necessarily the best approach. Because, to some extent, the content of the article may be truncated or rewritten in a certain way, causing the meaning to change from the original. To avoid this, readers can refer to the "chunking" technique.
In simple terms, "chunking" divides the article into segments to minimize input size. Embedding models only allow a relatively modest amount of input tokens, so we must find ways to reduce the number of input characters. There are many ways to split from easy to difficult.
The simplest way is to split based on a certain word count. For example, every 200 words split into one part, and so on until the end. This is quick but not optimal because the cut content may lie in two different parts. Therefore, there is a method called "sliding chunk," which means "buffering" a portion between the cut positions. For example, the first segment cuts the first 200 words, and the second segment also cuts 200 characters but lags back 50 characters from the first segment to capture more context, and so on until the end...
Additionally, there is another way to chunk based on meaning (semantic-based), which means dividing it into segments with meaning. This technique is more advanced and requires applying additional sentence and paragraph segmentation tools...
Initially, I intended to apply chunking along with summarization and divide the article into parts based on headings. Blogs have the advantage of relatively clear structure, divided into sections such as introduction, body, and conclusion. Within the body, they are further divided into smaller parts... And since each part is not long, if we split them further, the meaning will still be preserved. However, after some thought, I realized this might take too much time and could be left for later.
When a user performs a search on a short keyword phrase, typically 3 words or less, I prioritize keyword search first. If the entered keyword is longer, I will perform semantic search.
Try entering the phrase "node.js architecture," and you will see the order of results as shown below:
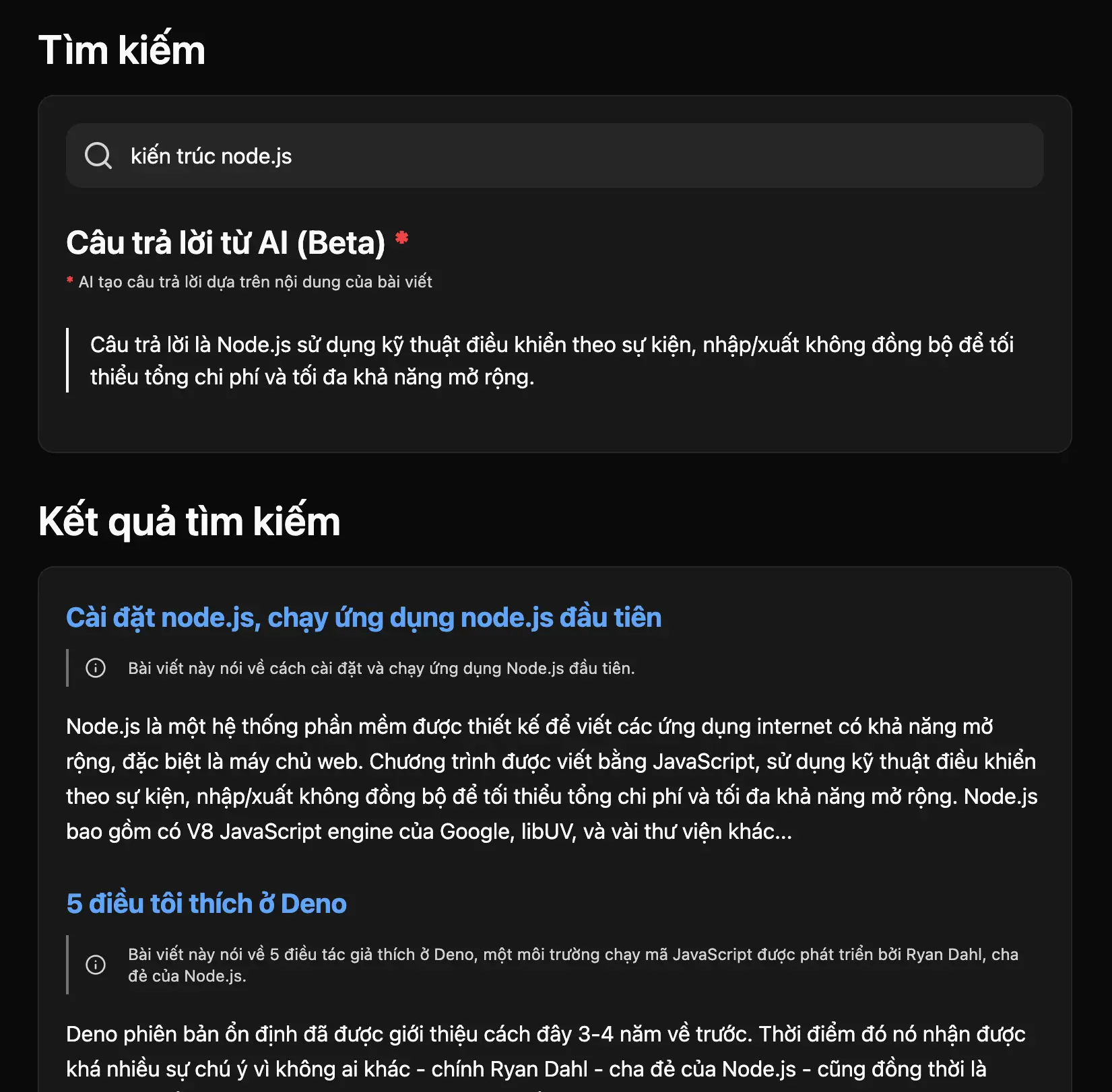
The first two results are unrelated, or at most, they only mention node.js but do not discuss node.js architecture; so why are they displayed at the top?
To explain this, it is because vector search is fundamentally mathematical calculations. Data that has been vectorized into numbers will be compared according to a certain formula to find similarities, for example, the shapes of them being as similar as possible or the distance between two vectors being as close as possible... The returned results are sorted in descending order. As shown, the likelihood is that the first two articles have the highest vector similarity, while in reality, they don't discuss the architecture of node.js at all.
So is there a way to solve this?
Yes! To rearrange the vector search results, we have another technique called rerank.
Rerank
Rerank aims to reassess the similarity between one text and other texts. Rerank is quite similar to vector querying because it receives a query and the text segments to compare, to determine which text is the most suitable. So why not simply use rerank instead of vector search?
Rerank is usually models trained to find and assess similarity. It can be said that rerank functions like large language models; it only receives input and output within a limited number of tokens. If there are thousands of articles, you cannot input all of them into rerank and ask it to find similarities among them. Thus, rerank usually complements vector search to arrange the relevance of search results.
As previously mentioned, after identifying related articles based on vector shapes, although they are arranged, that does not guarantee that the first results are semantically similar to the search query. At this point, we need the rerank model to rearrange the results once more.
After some research, I found the jina-reranker-v2-base-multilingual model, which is well-rated and also offers free usage. So I integrated it directly into the search function. After some time, the results appeared as shown in the image below.
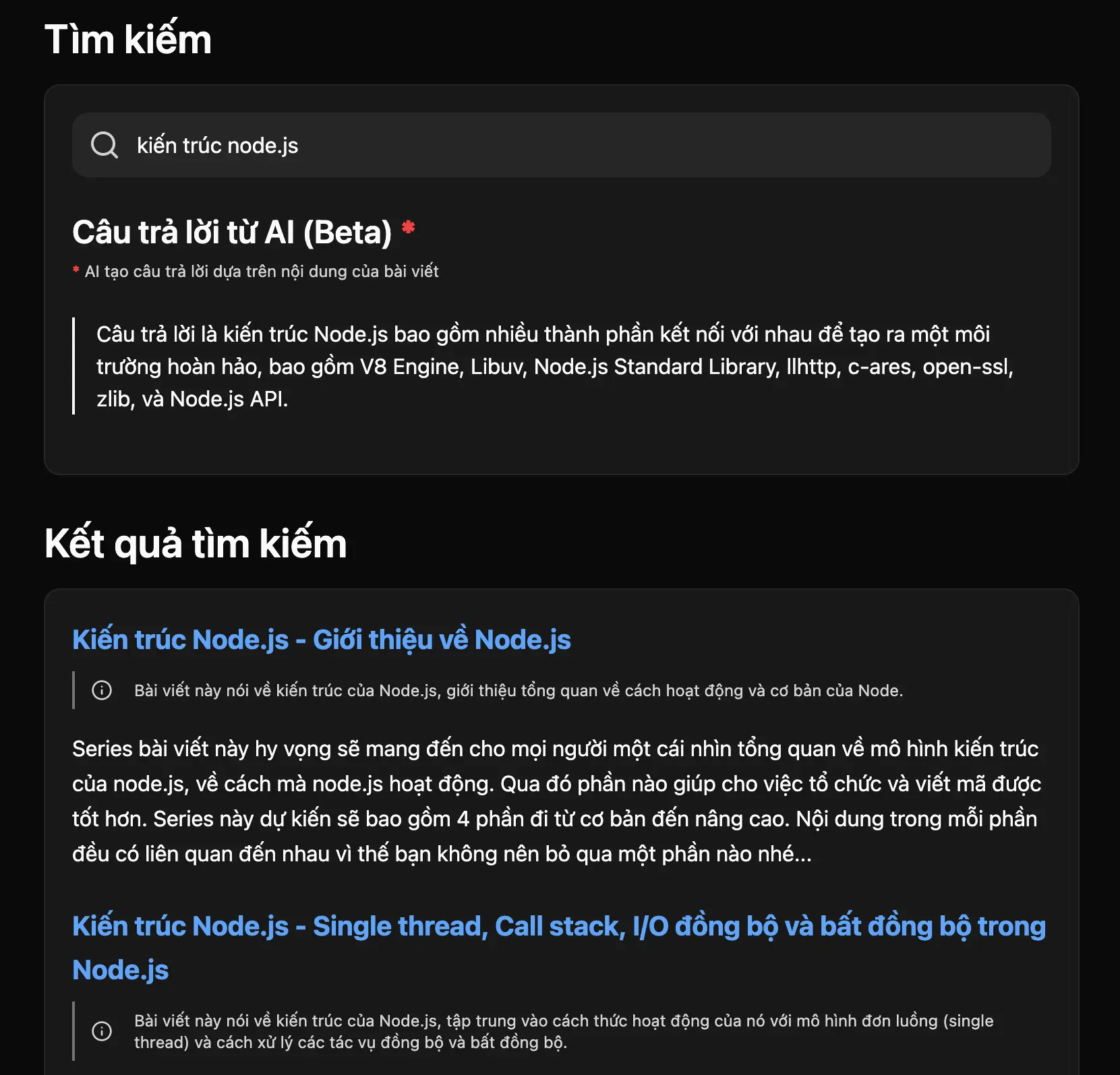
According to the documentation guidelines, jina receives a query field corresponding to the user's input data. documents is an array of texts used for evaluation, and I input 10 articles that are the results of the vector search, with top_n being the number of results that jina can return, which is a maximum of 10, so I input 10 to correspond with the 10 articles.
curl https://api.jina.ai/v1/rerank \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_5eebe24f08004f068bd72c9fdasfdcdaaaOQ5O0an3fsOIU2MKDANlzBUA_0Y9" \
-d @- <<EOFEOF
{
"model": "jina-reranker-v2-base-multilingual",
"query": "kiến trúc node.js",
"top_n": 3,
"documents": [
"Content of article 1...",
"Content of article 2...",
"Content of article 3...",
...
]
}
EOFEOF
Now the search feature seems to be more useful, and I will continue to monitor to optimize further if possible. Oh! This article was written before being deployed to production, so readers should try it again after a few minutes 😅.
Also, if you have any more effective search methods or are currently applying any, please leave a comment below the article for me and everyone to know. Thank you!