
Issues with Serverless Memory - Deno Deploy
Issues
Hanoi has entered autumn, the weather is no longer hot and harsh like summer, but instead, there are occasional rains. Rainy days are flooding, causing many troubles. I hate this kind of weather!
For over half a month now, my body has been quite "soft", a bit sluggish and frail. I don't want to exercise much, and my performance has gone down. Many days, I just want to lie down and take a nap after work. The next morning, I wake up with occasional headaches, and my working efficiency is reduced by half 🫣
Recently, I had an article about rewriting my blog from Nuxt to Fresh to reduce JavaScript code and increase page loading speed. In addition, I also moved my hosting from Cloudflare Worker to Deno Deploy, simply because Cloudflare does not support Fresh yet. The transition was smooth and quick because I already had experience deploying projects on serverless.
Deno Deploy is still relatively new. Sometimes, I receive reports of my website being down from monitoring tools. This has never happened on Cloudflare before. It's unacceptable for a serverless platform to experience downtime. But it doesn't happen often and is resolved quickly.
Lately, some readers have messaged me directly about being unable to access some articles. After checking, it seems that they have exceeded the memory limit. Every time I access, the log screen displays "Memory limit exceeded, terminated". Hmm... this has never happened on Cloudflare before.
As you know, serverless has a different memory allocation mechanism compared to traditional servers. We can't intervene in resource allocation and are only allocated a fixed amount by the provider. For example, each incoming request can only use 512KB of memory and 50ms of CPU processing time. If we exceed this, we have to pay extra to upgrade or receive an error message like I do.
Therefore, the problem lies in the logic. Perhaps I'm fetching too much data or creating too many variables, causing memory usage to increase. But what's strange is that not all articles are affected by this issue. Some articles don't experience this problem, and the common trait among affected articles is that they contain many markdown code blocks.
After re-examining my code, I think the problem lies in the convertMarkdownToHTML function. This function converts markdown text into HTML for display. Articles are stored as markdown text, and every time I read an article, convertMarkdownToHTML is called.
Inside convertMarkdownToHTML, there is the showdown-highlight library to apply syntax highlighting to markdown code blocks. Instead of plain black text, syntax highlighting makes the code more colorful. showdown-highlight adds some HTML and CSS tags to add color. I suspect that the problem lies here. The more complex the markdown code block, the more memory is used.
After applying the fix to 1-2 articles, the error no longer occurs. I believe my suspicion is correct. However, just as I was about to breathe a sigh of relief, I saw that the number of affected articles is much higher than I expected. If I continue to apply this fix, the quality of the articles will suffer. Removing markdown code blocks means reducing the content quality, and writing about programming without showing code is meaningless!?
Hmm, is it possible that just fetching data from the database uses up all the memory?
I even looked into whether fetching data from the database increases memory size. Apart from the convertMarkdownToHTML function, there are many code blocks that fetch suggested articles, comments, and create variables to handle logic... If it's that much, it's like measuring every variable to see how much memory it occupies.
A turning point came when I discovered that an article with very little text also experienced the same issue. This means that the problem doesn't depend on the length of the article content but might be due to some code block using more memory. Therefore, there must be a way to monitor memory allocation in Deno to determine where the problem lies.
The DevTools in the browser have a tool to help us monitor allocated memory. Opening DevTools, going to "Memory" and looking at the "Allocation sampling" option, it allows us to observe memory allocation during execution. Fortunately, Deno still uses V8, so we can enable debugging to use this feature.
I found a way to enable debugging in Deno. It's simple, just add the --inspect flag before the run command, and the debugging process is very similar to Node.js.
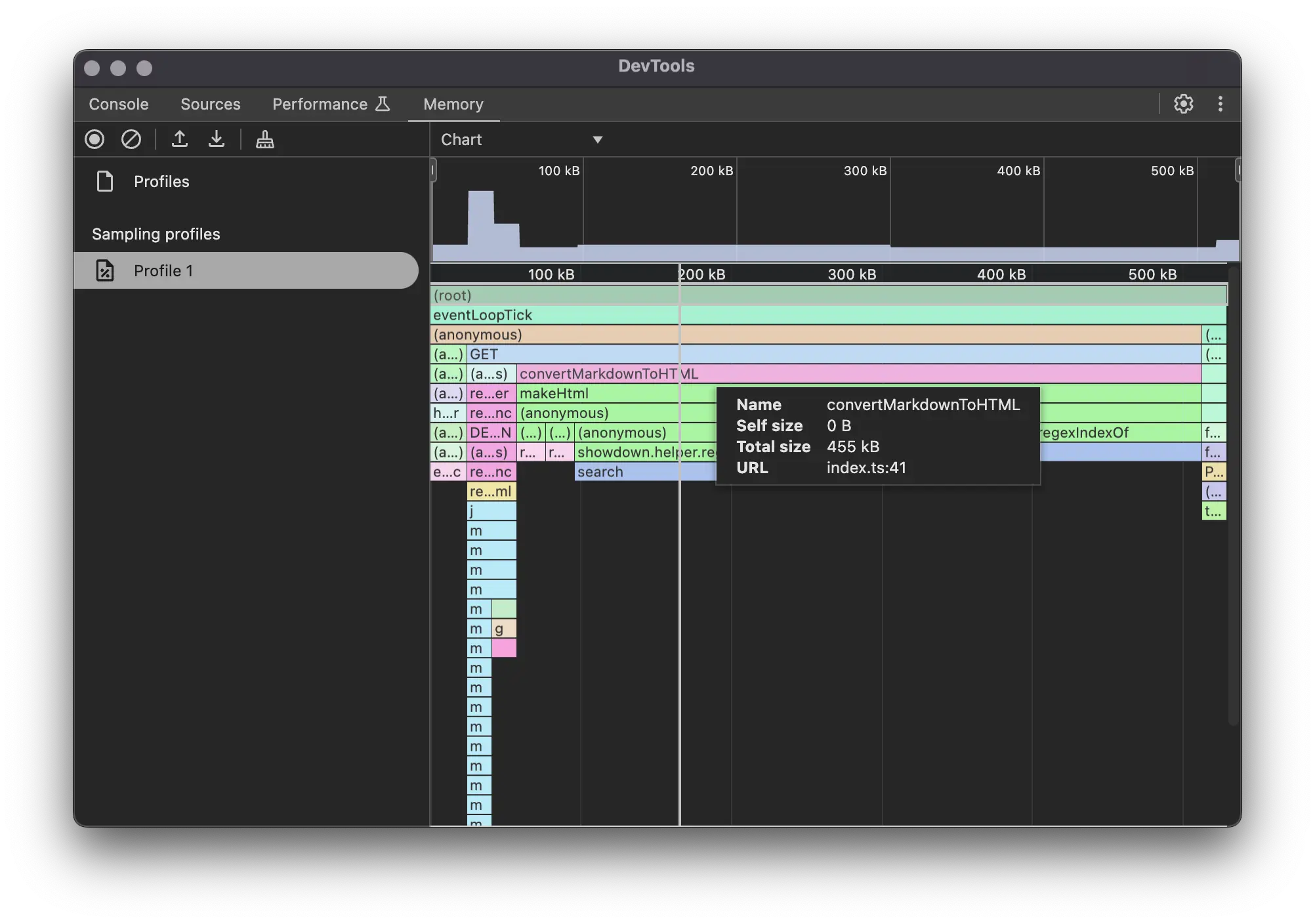
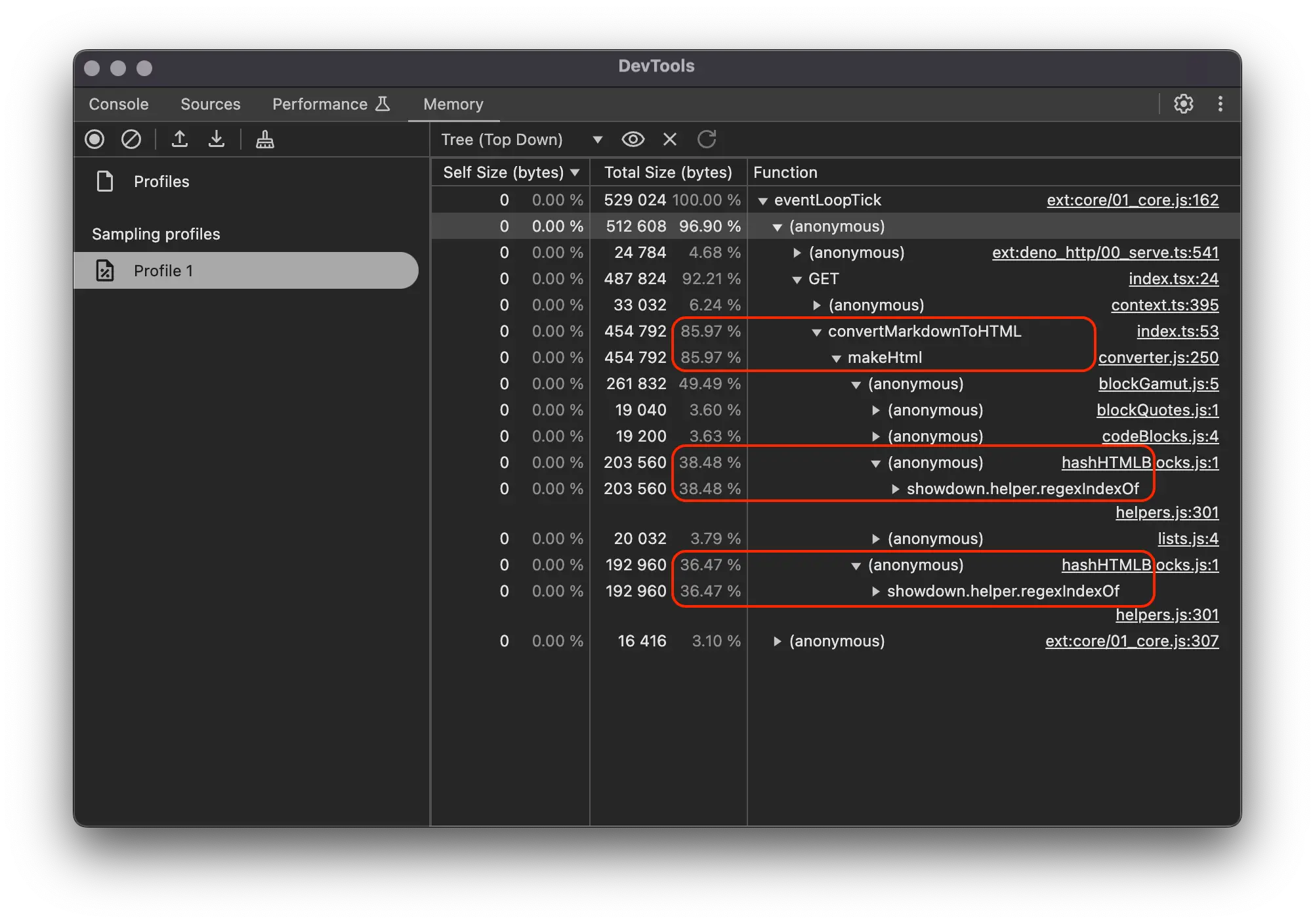
Here, after analyzing the chart, I found that the convertMarkdownToHTML function is using a lot of memory, up to 86% of the total memory in this processing session. When compared to articles that don't experience the error, the number is only around 20%. Continuing to analyze inside convertMarkdownToHTML, I discovered that the showdown library requires a lot of memory to parse markdown to HTML. Finally, I concluded that articles with more complex markdown code blocks are more likely to experience this issue.
At this point, many people might think that switching to another library is the solution. However, I think the opposite. One reason is that I've already spent effort configuring this library to parse specific code segments in the way I want. If I switch to another library, I'll have to find a way to parse the content similarly, which takes time and poses the risk of breaking parsing in other articles.
The most feasible solution is to separate the markdown parsing service, stop calling the convertMarkdownToHTML function every time an article is rendered. Instead, create an additional column to store HTML content for each article.
With just a few lines of code, I separated the convertMarkdownToHTML function into a project using hono.dev and deployed it to Cloudflare Worker. Then, I added logic to the API to create/update articles, turning the convertMarkdownToHTML function into an API call to the new service, storing new HTML content. At the same time, I removed the old convertMarkdownToHTML function.
Everything is now working again!
Conclusion
This issue highlights that serverless resources are limited, and we can't use them as freely as on traditional servers. We need to be cautious in data processing and optimize everything as much as possible to avoid issues during operation.