
ChatGPT API and New Challenges in the Translation Battle
The Issue
A couple of weeks ago, I wrote an article about the process of integrating ChatGPT into AdminCP to translate articles from Vietnamese to English for the purpose of creating a multilingual website. Recently, ChatGPT has officially opened up registration and widespread usage for users in Vietnam, and users can now purchase the Plus version or deposit money into their accounts to meet their API usage needs. This piqued my curiosity.
In the current situation, the translation feature in AdminCP is working relatively well, although occasionally ChatGPT "slips up" and translates my formatting a bit incorrectly, but that issue is not too serious, just takes some time to delete that "humorous" response and request again. As I mentioned, ChatGPT has allowed users in Vietnam to pay to use the API, and I also want to try out how it works and how much it costs. If there is any future need, then I will have the experience to deploy it.
With that in mind, this past weekend I experimented with the new API and tried integrating it into AdminCP as an upgrade.
The Issue with the Old Library
In the old library, namely transitive-bullshit/chatgpt-api, I used the ChatGPTUnofficialProxyAPI method to initialize an "unofficial" ChatGPT version. Because I couldn't use OpenAI's API keys at the time and had to use an Access Token to interact with ChatGPT. Simply put, using API Keys allows interaction with the API, while using an Access Token is like using its chat (UI) interface at chat.openai.com, which is why it's called "unofficial".
Interacting with ChatGPT at this time is no different from when having a conversation through its UI.
In the library, there is also the ChatGPTAPI method for interacting with the "real" ChatGPT API. After acquiring API keys, I tried switching from ChatGPTUnofficialProxyAPI to ChatGPTAPI, because according to the documentation, the methods in these two classes are quite similar, both have sendMessage to start sending a message, so I thought the transition process would be quick.
But for some reason, no matter if it's due to bad luck or other factors, I couldn't get it to work. Specifically, after initializing ChatGPTAPI and calling sendMessage, the response I received was completely off from the question. I can't recall the exact answer I received, but the general idea was that it apologized for being an AI with information only up to date XX and couldn't answer this question!
const api = new ChatGPTAPI({ apiKey: process.env.OPENAI_API_KEY })
// send a message and wait for the response
let res = await api.sendMessage('What is OpenAI?')
console.log(res.text)
To avoid wasting more time, I consulted the OpenAI documentation at API reference - OpenAI. There, I found the API list for ChatGPT conversations and the official library called openai.
It was time for me to switch to the new library and see how it worked.
The Issue with the New Library
Setting up a simple example was not difficult, thanks to the existing documentation, I just copied it, replaced the API keys, and checked if it worked.
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: 'My API Key',
});
async function main() {
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: 'gpt-3.5-turbo',
});
}
Oh, it responded like a real ChatGPT, which means everything was working as intended.
Remembering the previous implementation, there were two methods sendMessage and sendNext corresponding to sending a message and continuing the conversation. If you use ChatGPT on the UI, when the answer is too long, ChatGPT stops and you need to click the "Continue" button to receive the rest of the answer. These two methods simply simulate this behavior.
As planned, I also re-implemented these two methods. But I couldn't find any API to perform the "Continue" behavior. Strange, then how do I prompt ChatGPT to continue its answer?
Thinking about it, I first wrote the sendMessage method, then sent a message requesting it to translate an article longer than 1000 words. It wasn't wrong, after waiting for a few minutes, I received a response, but it wasn't complete. I then immediately sent another message requesting it to continue its answer, but it didn't understand what I wanted. At this point, many abnormalities started to appear, such as conversation ID, parent ID... or in other words, the previous context that needed to be sent to ChatGPT for it to understand the conversation content.
I wandered and searched for answers, finally finding out how to pass the context back to it. If you converse with ChatGPT on the UI, it will divide it into conversations with the full conversation content. So if you continue the conversation, it still understands the previous context to give accurate answers. But direct calls to the API are different, there are no saved messages, no context to understand, so to make ChatGPT understand the context you're creating, you have to resend everything.
const chatCompletion = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: 'Say this is a test' }],
});
Pay attention to messages, which is an array of data, it has roles and content representing the message. We have three roles: system, user, and assistant, representing system messages, user messages, and ChatGPT messages. This combination of roles creates a specific context that ChatGPT can use to analyze and provide accurate answers.
Based on that, I need to pass in all the content from the beginning of the questioning and even its own replies for it to understand. I created a variable messages as an array, and every time I asked or received a response, I would push the content into the array and send it in the next call. Just when I thought it was done, another error appeared: "This model's maximum context length is 4097 tokens".
Continuing my search, I found that this error was due to sending too long of a character sequence to ChatGPT. In the article Integrating ChatGPT into Article Translation in AdminCP, I mentioned the concept of tokens in OpenAI and made the rough association that 1 token could be considered equivalent to 1 word. However, this is not entirely accurate. To accurately estimate the number of tokens from a character string, readers can visit the tokenizer - OpenAI page to check for themselves. Going back to the issue at hand, because I was translating long articles with a large number of characters, the number of tokens also increased, causing ChatGPT to refuse processing.
I found several suggestions that I should ask ChatGPT to summarize the previous conversation, then store and send it for future use. This ensures storage with a small payload while still providing some context for it to understand the previous conversation. However, this seems ineffective for translation, as it's not possible to summarize and ask it to continue. So the advice is to split the article into smaller chunks and translate them one by one. Well, that means there are many things to handle, such as calculating the number of tokens, dividing the article into meaningful blocks for more accurate translation... But if there is no other way, I have to do it.
Curiously, I studied the openai.chat.completions.create method and discovered that the model parameter accepts some models with larger input sizes, as shown in the image below:
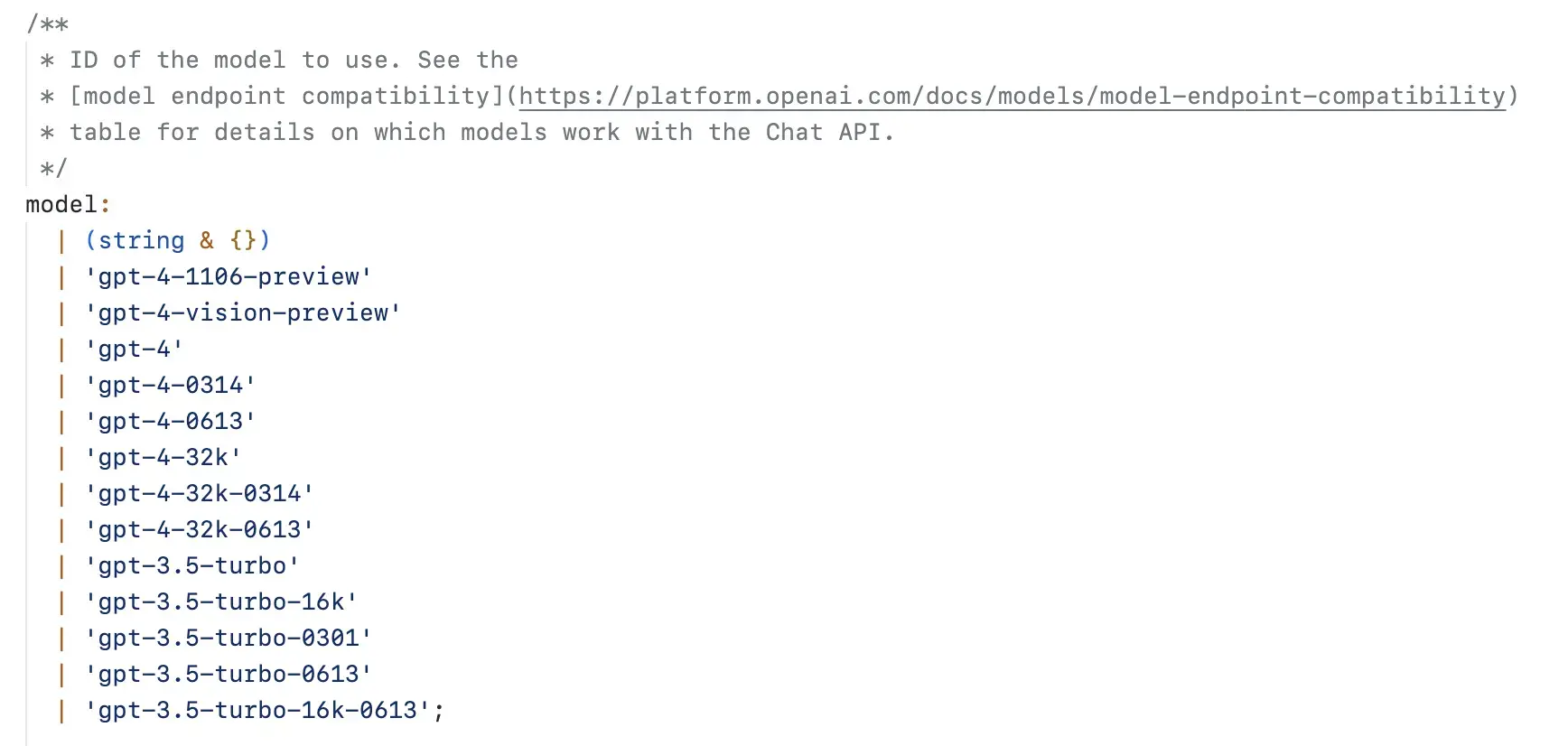
Therefore, when I switched the default model from gpt-3.5-turbo to gpt-3.5-turbo-16k, it was great, everything worked normally. At this point, I understood that besides the larger context number making ChatGPT smarter, it could also accept longer inputs and responses. However, as a tradeoff, it would be more expensive.
Everything is Working
By then, setting up ChatGPT via the new API was almost complete. But there was one issue: the response time was quite long. While waiting and unsure whether it would succeed or fail, I passed the additional stream: true option in the create function to receive the response stream. Combining it with creating a socket server using the socket.io library would allow the response to be streamed sentence by sentence and character by character, allowing tracking of the translation process.
const stream = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: 'Say this is a test' }],
stream: true,
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0]?.delta?.content || '');
}
While ChatGPT was responding and I wanted to stop it, even after trying to "kill" the server, I still had to wait a long time before receiving a response. I speculated that turning off the server didn't completely require ChatGPT to stop responding to the previous question. Therefore, I had to wait for it to finish before the next request could be processed. This was wasteful because OpenAI would still charge for the output even if we no longer needed that response.
Fortunately, the library provides an abort function to request ChatGPT to stop responding. Readers can refer to the documentation for how to implement this function to avoid wasting tokens in the future.