
Tối ưu hoá tìm kiếm ngữ nghĩa
Vấn đề
RAG (Retrieval-Augmented Generation) là một phương pháp kết hợp giữa truy xuất thông tin (retrieval) và tạo văn bản (generation) để cải thiện chất lượng và độ chính xác của các câu trả lời do mô hình ngôn ngữ sinh ra. Cách hiểu đơn giản nhất về RAG là hãy hình dung về việc khi chat với ChatGPT, nó gần như trả lời được tất cả câu hỏi mà bạn đưa ra. Sở dĩ nó có kiến thức uyên thâm như vậy vì được huấn luyện từ nhiều nguồn dữ liệu. Đó vừa là ưu mà cũng vừa là nhược: Ưu là cái gì cũng biết; nhược là đôi khi không biết điều, trả lời chung chung. RAG thì ngược lại, làm cho các mô hình ngôn ngữ giới hạn lượng kiến thức, hoặc chỉ học và trả lời câu hỏi trên một tập dữ liệu có hạn mà chúng ta cung cấp. Nghe thì có vẻ đơn giản nhưng sự thật thì lại rất phức tạp.
RAG ngày càng nhận được nhiều sự quan tâm bởi vì nếu làm chủ được công nghệ này sẽ mang lại nhiều lợi ích. Trong số đó có thể kể đến khả năng tăng cường tính chính xác của câu trả lời. Đào tạo mô hình dựa trên tập dữ liệu của chúng ta và dễ dàng truy xuất ngược trở lại. Nó có thể ứng dụng trong rất nhiều trường hợp như tìm kiếm theo ngữ nghĩa, giải thích, trả lời thông minh và tóm tắt nội dung... trên tập dữ liệu xác định.
Một ví dụ về RAG mà tôi thấy ấn tượng nhất chắc phải kể đến NotebookLM. Công cụ này giúp chúng ta khai thác dữ liệu dựa trên những gì đưa cho, và nó chỉ trả lời dựa trên nội dung được cung cấp. Ví dụ, cho một liên kết đến bài viết bất kỳ, ngay lập tức nó sẽ tóm tắt lại nội dung, gợi ý các chủ đề, câu hỏi có thể khai thác từ bài viết này, hoặc trao đổi trực tiếp bằng cách đặt bất cứ câu hỏi nào.
Tính năng tìm kiếm theo ngữ nghĩa mà tôi làm cách đây không lâu cũng có thể coi là một ứng dụng nhỏ về RAG. Việc áp dụng các mô hình ngôn ngữ lớn, mô hình embedding, tóm tắt, chuyển nội dung thành vector, lưu trữ trong cơ sở dữ liệu và truy vấn. Cuối cùng đưa ra câu trả lời là các bài viết có nội dung liên quan đến những gì mà người dùng đang tìm kiếm, cách xử lý khác hẳn với full-text search trước đây.
Sau khi phát hành một thời gian, tôi đã lên kết hoạch theo dõi và phân tích hành vi người dùng khi họ sử dụng chức năng tìm kiếm. Xem liệu tính năng mới này có giúp ích được cho họ hoặc nó có hoạt động được như mong đợi không. Thì phát hiện ra một số điều bất cập như sau.
Trong tổng 130 lượt tìm kiếm, có 100 lượt tìm kiếm theo ngữ nghĩa (semantic search), 30 lượt tìm kiếm theo từ khoá (full-text search). Khi nhập nội dung và nhấp tìm kiếm, trang web sẽ ưu tiên tìm kiếm theo ngữ nghĩa đầu tiên. Nếu không có kết quả hoặc người dùng không tìm thấy câu trả lời thoả đáng, họ có thể bấm vào "tìm kiếm theo từ khoá" để chuyển sang trường hợp tìm kiếm full-text. Như vậy có nghĩa là chưa đến 1/3 bấm vào tìm kiếm theo từ khoá. Ồ! Liệu có phải tìm kiếm theo ngữ nghĩa đã đủ tốt để khiến họ không cần chuyển sang tìm kiếm theo từ khoá nữa? Rất nhiều khả năng là... Không!
Khi đi sâu vào nội dung tìm kiếm của người dùng. Tôi phát hiện ra phần lớn người dùng đang thử tìm kiếm theo từ khoá. Tức là họ chỉ nhập vào các từ hoặc cụm từ hết sức ngắn gọn. Ví dụ như node.js, redis, jwt, module, commonjs... Các từ khoá ngắn như thế này đa phần tìm kiếm theo ngữ nghĩa sẽ không tìm thấy câu trả lời vì dữ kiện quá ngắn, không đủ để truy vấn vector tìm ra được sự tương đồng, hoặc gây nhiễu. Đối với tìm kiếm theo từ khoá, full-text search cho kết quả tốt hơn.
Tôi rút ra một kết luận: khi người dùng nhập vào một từ khoá ngắn, có thể họ chỉ đang muốn tìm những bài viết có chứa từ khoá đó. Ngược lại, khi họ nhập một câu hỏi hoặc một từ khoá dài hơn, có chứa ngữ cảnh, thì nhiều khả năng họ đã xác định rõ được vấn đề, lúc này tìm kiếm theo ngữ nghĩa có lẽ mới phù hợp.
Bên cạnh đó cũng ghi nhận một số trường hợp mang thiên hướng tìm kiếm theo ngữ nghĩa, ví dụ như "kiến trúc node.js", "sửa commit chưa push"... Mỗi khi nhận được các tìm kiếm kiểu như vậy, tôi thường thử tìm lại xem các kết quả mà người dùng nhìn thấy là gì để lên kế hoạch tối ưu hoá lại kết quả tìm kiếm.
Nhận ra có nhiều kết quả không được như mong đợi, nên cuối tuần vừa rồi dành thời gian xem lại tính năng này.
Tối ưu hoá tìm kiếm theo ngữ nghĩa
Trước khi tiếp tục, xin nhắc lại một chút về cách làm trước đó!
Đầu tiên nhờ các mô hình LLMs tóm tắt lại nội dung chính của bài viết. Nếu bài viết có độ dài từ 1.000 đến 2.000 từ, thì sau khi tóm tắt, nội dung còn lại chỉ nằm ở mức trên dưới 500 từ. Sau đó sử dụng mô hình embeddings của nomic để chuyển thành vector, lưu vào cơ sở dữ liệu Supabase để tiện truy vấn. Vectors lúc này có kích thước 768, cân bằng giữa ngữ nghĩa và tốc độ tìm kiếm.
Tóm tắt lại nội dung chính rồi "vector hoá" chưa hẳn là cách làm tốt nhất. Vì ít nhiều nội dung của bài viết sẽ bị cắt xén hoặc bị viết lại theo một hướng nào đó, khiến cho ngữ nghĩa bị thay đổi so với lúc ban đầu. Để tránh trường hợp này, bạn đọc có thể tham khảo thêm kỹ thuật "chunking".
Hiểu đơn giản thì "chunking" chia bài viết thành các đoạn để làm nhỏ đầu vào. Các mô hình embedding chỉ cho phép một lượng tokens đầu vào tương đối khiêm tốn, vì thế buộc chúng ta phải tìm cách giảm thiểu số lượng ký tự đầu vào. Có rất nhiều cách chia từ dễ đến khó.
Cách đơn giản nhất là chia theo số lượng từ nhất định. Ví dụ cứ mỗi 200 từ thì chia thành một phần, cứ thế cho đến hết. Cách này nhanh nhưng không tối ưu vì nội dung bị cắt có thể nằm ở 2 phần khác nhau. Thế nên người ta lại có cách gọi là "chunk trượt", tức là "buffering" một khoảng giữa vị trí cắt. Ví dụ đoạn 1 cắt 200 từ đầu tiên, đoạn 2 cũng cắt 200 ký tự nhưng lùi về 50 ký tự ở đoạn một để lấy thêm ngữ cảnh, cứ như thế cho đến hết...
Ngoài ra còn một cách nữa là chunk theo ngữ nghĩa (semantic-based), tức là chia thành các đoạn có ngữ nghĩa. Kỹ thuật này nâng cao hơn và phải áp dụng thêm một số công cụ tách câu, tách đoạn...
Ban đầu tôi định áp dụng thêm chunking. Song song với tóm tắt thì chia nhỏ bài viết thành các phần dựa theo đầu mục. Blog có một lợi thế là bài viết được bố cục tương đối rõ ràng, chia thành các phần như mở bài, thân bài, kết bài. Trong thân bài thì lại chia thành các phần nhỏ hơn... Mà mỗi phần thì cũng không dài, nên nếu chia nhỏ ra thì vẫn đảm bảo được ý nghĩa. Nhưng suy đi tính lại, việc làm này hơi mất thời gian, có thể để làm sau.
Khi người dùng thực hiện tìm kiếm trên một cụm từ khoá ngắn, thường là 3 từ trở xuống thì ưu tiên tìm kiếm theo từ khoá trước. Nếu từ khoá nhập vào dài hơn thì thực hiện tìm kiếm theo ngữ nghĩa.
Thử nhập vào cụm từ "kiến trúc node.js", bạn sẽ nhìn thấy thứ tự kết quả như hình dưới đây:
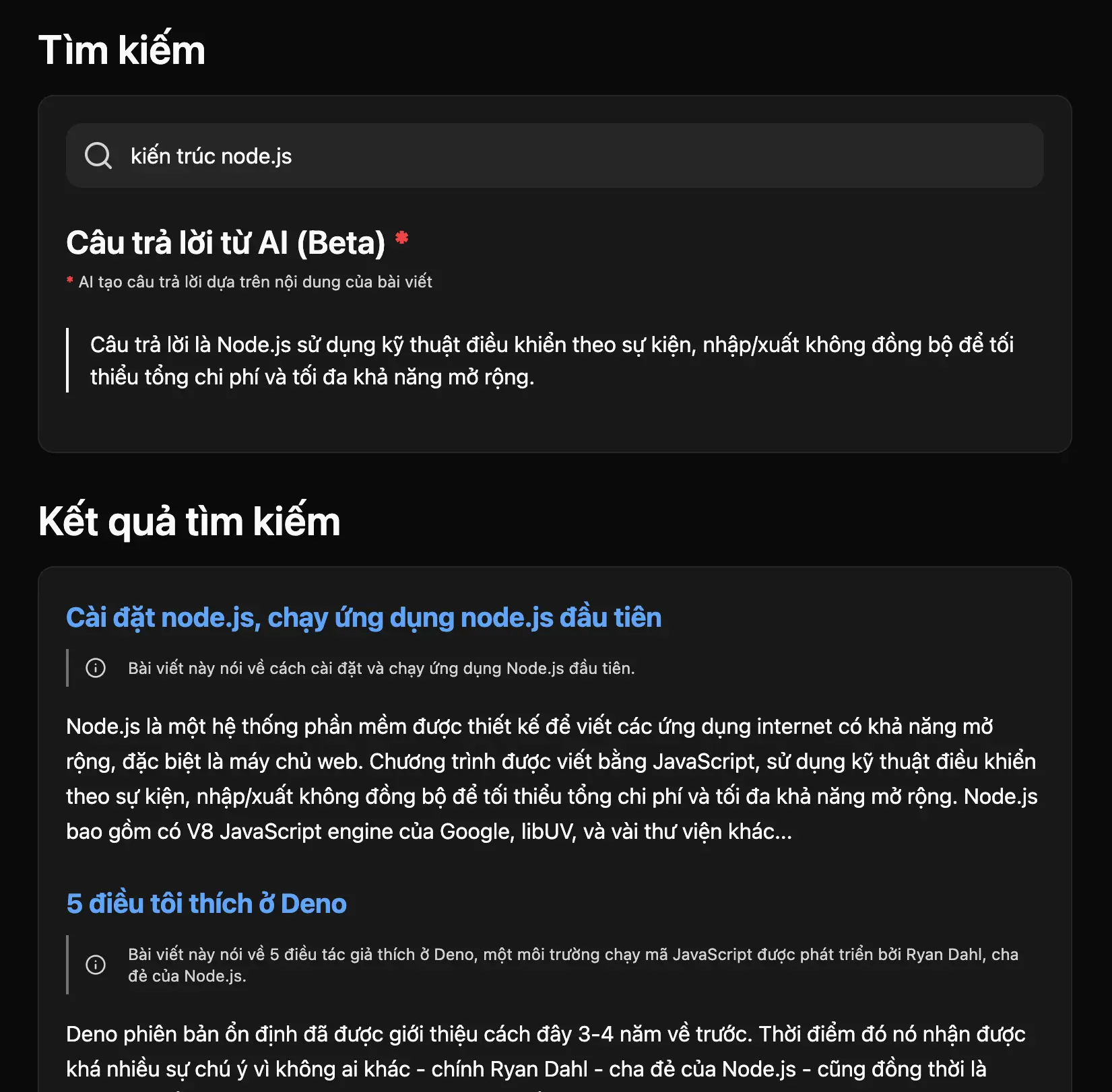
2 kết quả đầu tiên không liên quan, hoặc cùng lắm là nó chỉ nhắc đến node.js chứ không nói về kiến trúc node.js, vậy tại sao nó lại được hiển thị lên đầu?
Để lý giải cho điều này, bởi vì tìm kiếm vector về cơ bản là các phép tính toán học. Dữ liệu sau khi được vector hoá thành các con số sẽ được so sánh với nhau theo một công thức nào đó để tìm ra sự tương đồng, ví dụ như hình dạng của chúng càng giống nhau càng tốt hoặc khoảng cách giữa 2 vector càng gần càng tốt... kết quả trả về được sắp xếp theo thứ tự giảm dần. Giống như trên, khả năng là 2 bài viết đầu tiên có độ tương đồng vector cao nhất, trong khi thực tế chúng lại chẳng nói về kiến trúc của node.js.
Vậy có cách nào giải quyết không?
Có! Để sắp xếp lại kết quả tìm kiếm vector, chúng ta lại có thêm một kỹ thuật nữa gọi là rerank.
Rerank
Rerank nhằm xác định lại độ tương đồng giữa một văn bản với các văn bản khác. Rerank khá giống với truy vấn vector vì nó đều nhận một câu truy vấn và các đoạn văn bản cần so sánh, để đưa ra kết quả là văn bản nào phù hợp nhất. Thế thì tại sao không dùng luôn rerank thay thế cho vector search nhỉ?
Rerank thường là các mô hình được đào tạo để tìm và xác định độ tương đồng. Có thể nói rerank hoạt động như các mô hình ngôn ngữ lớn, nó chỉ nhận đầu vào và đầu ra ở một số lượng tokens nhất định. Nếu có hàng ngàn bài viết, không thể cho hết vào rerank và nhờ nó tìm ra được sự tương đồng trong số đó. Nên rerank thường bổ trợ cho tìm kiếm vector để sắp xếp lại mức độ tương đồng của kết quả tìm kiếm.
Như ở trên đã đề cập, sau khi tìm ra các bài viết liên quan dựa vào hình dạng vector. Mặc dù đã sắp xếp nhưng điều đó không đảm bảo rằng những kết quả đầu tiên là tương đồng về mặt ngữ nghĩ với mẫu tìm kiếm. Lúc này chúng ta cần nhờ đến mô hình rerank sắp xếp lại kết quả một lần nữa.
Sau một hồi tìm hiểu, tôi tìm thấy mô hình jina-reranker-v2-base-multilingual được đánh giá tốt, đặc biệt còn cho dùng miễn phí. Nên tích hợp luôn vào chức năng tìm kiếm. Sau một hồi thì kết quả như trong hình ở dưới đây.
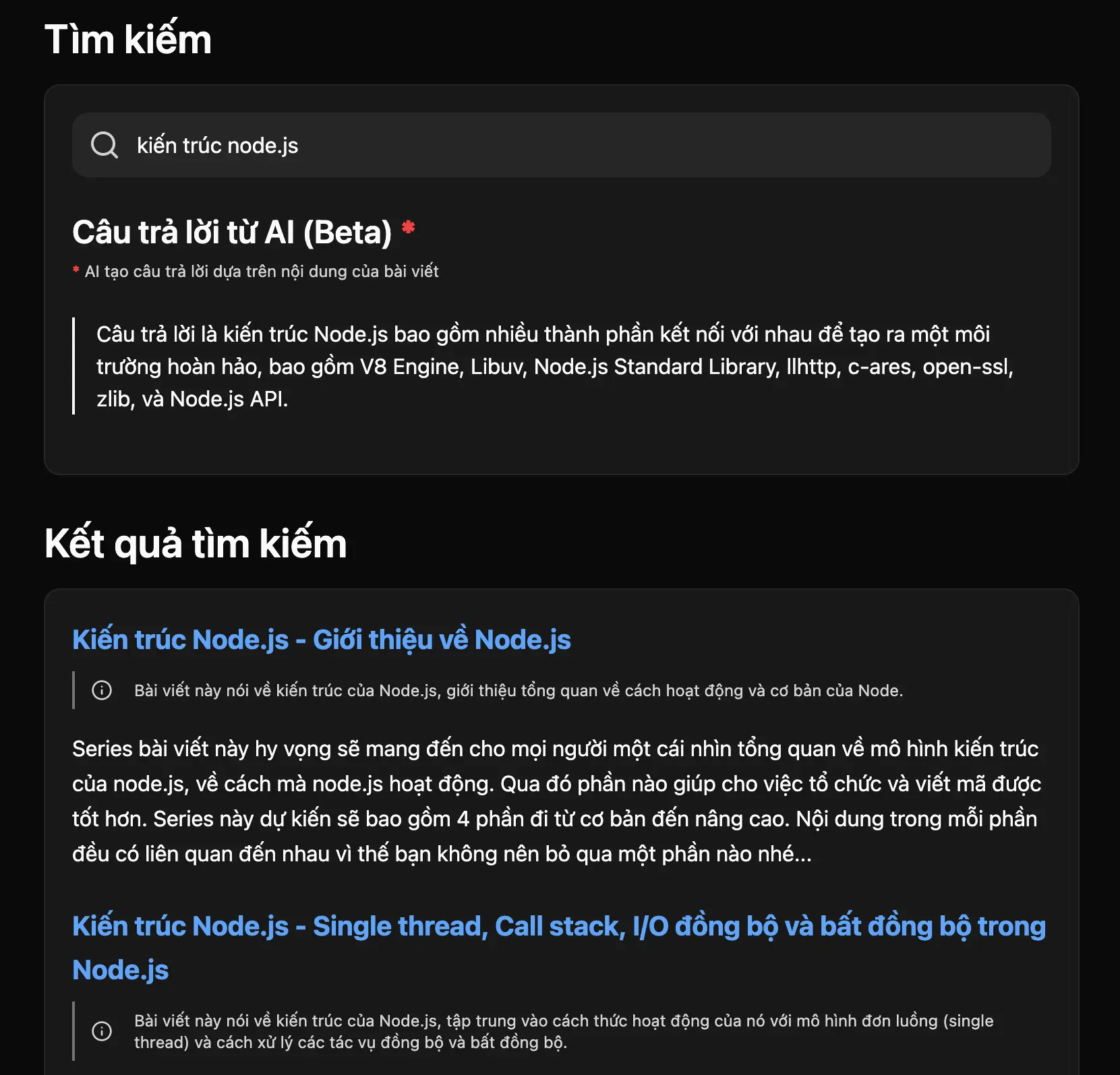
Theo hướng dẫn trong tài liệu, jina nhận vào một trường query tương ứng với dữ liệu nhập vào của người dùng. documents là một mảng các văn bản dùng để đánh giá, tại đây tôi truyền vào 10 bài viết là kết quả của tìm kiếm vector, top_n là số lượng kết quả mà jina có thể trả về, tối đa là 10 nên nhập vào 10 để tương ứng với 10 bài viết luôn.
curl https://api.jina.ai/v1/rerank \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_5eebe24f08004f068bd72c9fdasfdcdaaaOQ5O0an3fsOIU2MKDANlzBUA_0Y9" \
-d @- <<EOFEOF
{
"model": "jina-reranker-v2-base-multilingual",
"query": "kiến trúc node.js",
"top_n": 3,
"documents": [
"Nội dung bài viết 1...",
"Nội dung bài viết 2...",
"Nội dung bài viết 3...",
...
]
}
EOFEOF
Bây giờ tính năng tìm kiếm có vẻ đã hữu ích hơn một chú, tôi sẽ tiếp tục theo dõi để tối ưu thêm nếu có thể. À! bài viết này được viết ra trước thời điểm triển khai lên production nên bạn đọc thử lại sau ít phút 😅.
Ngoài ra nếu bạn còn phương pháp nào tìm kiếm hiệu quả hơn, hoặc đang áp dụng thì hãy để lại bình luận xuống phía dưới bài viết cho tôi và mọi người cùng biết nhé. Xin cảm ơn!