
Thực hành xử lý dữ liệu bằng cách sử dụng lệnh trên tệp sao kê MTTQVN
Vấn đề
Mới đây Ủy ban Trung ương Mặt trận Tổ quốc Việt Nam (MTTQVN) đã đăng tải 12.028 trang sao kê tiền ủng hộ đồng bào bị ảnh hưởng do bão số 3. Ngay sau đó là nhiều cuộc thảo luận sôi nổi xoay quanh chủ đề này trên nổ ra trên mạng xã hội. Và nhanh như chớp, đã có nhiều người làm ra các trang web tra cứu thông tin sao kê. Chỉ cần nhập bất cứ nội dung nào vào ô tìm kiếm, bấm nút, đợi một lát thì dữ liệu tìm thấy sẽ được hiển thị lên màn hình.
Như chúng ta đã biết, tệp tin sao kê của MTTQVN ở định dạng pdf cho nên ắt hẳn máy chủ của các trang web truy xuất đã qua một bước tiền xử lý dữ liệu. Cách dễ nhất mà tôi có thể nghĩ ra được là bóc tách dữ liệu thành các dòng văn bản, nội dung có cấu trúc, đưa vào một loại cơ sở dữ liệu nào đó như SQL rồi sử dụng các câu lệnh truy vấn để tìm kiếm. Thế là bài toán đã có lời giải.
Sau khi thử nghiệm tìm kiếm trên một trang web tra cứu thông tin sao kê. Có vẻ như lượng người truy cập thời điểm đó đang rất đông nên máy chủ liên tục bị báo lỗi 500. Hmm, với một người yêu thích tốc độ thì đây quả là một trải nghiệm tồi. Tự nhiên lúc đó trong đầu tôi nảy ra một ý tưởng: Mình sẽ tự làm một công cụ tìm kiếm dữ liệu ngay trên chiếc máy tính này, chẳng phải sẽ nhanh và chính xác hơn hay sao!
Nghĩ là làm, tôi lên mạng tìm kiếm tệp sao kê. Nó được lưu trữ trên Google Drive. Hớn hở bấm tải xuống thì thật oái oăm làm sao khi Google cảnh báo tệp này đã được tải xuống quá nhiều, khả năng cao phải chờ trong vòng 24h giờ nữa thì mới có thể tải xuống!? Rồi lúc đó liệu khí thế của mình có còn như lúc này nữa để mà làm hay không!!!
Nhưng kiểu gì thì kiểu, chắc chắn đã có người tải được tệp sao kê về rồi, và họ sẽ tải lên đâu đó. Tôi tìm kiếm theo tên của tệp sao kê thì cuối cùng cũng tải nó về được. Nhưng với một tệp pdf thì không dễ để trích xuất thông tin cho nên cần phải chuyển đổi nó sang định dạng khác như csv chẳng hạn. csv là quá hoàn hảo trong nhiều trường hợp xử lý dữ liệu.
Tôi sử dụng một vài công cụ chuyển đổi định dạng trực tuyến nhưng có vẻ nó không được chính xác cho lắm. Đang định viết một đoạn mã để trích xuất thông tin thì lại nghĩ: Chắc là có người làm rồi nên mình có thể không phải mất thời gian làm lại nữa. Quả đúng như vậy, chỉ trong một vài bước tìm kiếm, toidicodedao đã chia sẻ tệp csv sao kê này trong một bài đăng trên Facebook. Gửi một lời cảm ơn sâu sắc rồi nhanh chóng tải nó xuống.
Được rồi, dữ liệu đã có đầy đủ. Từ bây giờ hãy bắt đầu quá trình khám phá dữ liệu với tôi. Nhưng không phải là đưa chúng vào cơ sở dữ liệu rồi thực hiện các câu lệnh tìm kiếm nữa, mà có một cách nhanh và dễ dàng hơn là tận dụng sức mạnh của những dòng lệnh trong Linux.
Nhưng trước tiên, tôi hy vọng rằng bạn đọc đã biết một số công cụ dòng lệnh hữu ích trong Linux như cat, grep, head, tail, sort... cùng một số lệnh nâng cao khác như sed và awk. Cũng chẳng cần phải biết cách sử dụng đâu mà chỉ cần biết nó dùng để làm gì là được rồi. Vì sau đó nếu thấy thích, bạn sẽ tự biết cách để học cách sử dụng chúng.
Thực hành
Đầu tiên hãy thử tìm kiếm giao dịch theo tên của một ai đó, tệp tin tải về trước đó có tên là transactions.csv. Ở đây tôi thử tìm kiếm với cái tên "tran thi thuy linh". Cách đơn giản nhất là sử dụng cat kèm grep.
$ cat transactions.csv | grep "tran thi thuy linh"
Không có kết quả nào được tìm thấy, đơn giản vì grep đang phân biệt hoa/thường. Để không phân biệt khi tìm kiếm, thêm một cờ i sau grep:
$ cat transactions.csv | grep -i "tran thi thuy linh"
Tuy vậy đây chưa phải là cách tốt nhất, thay vào đó hãy dùng trực tiếp grep.
$ grep -i "tran thi thuy linh" transactions.csv
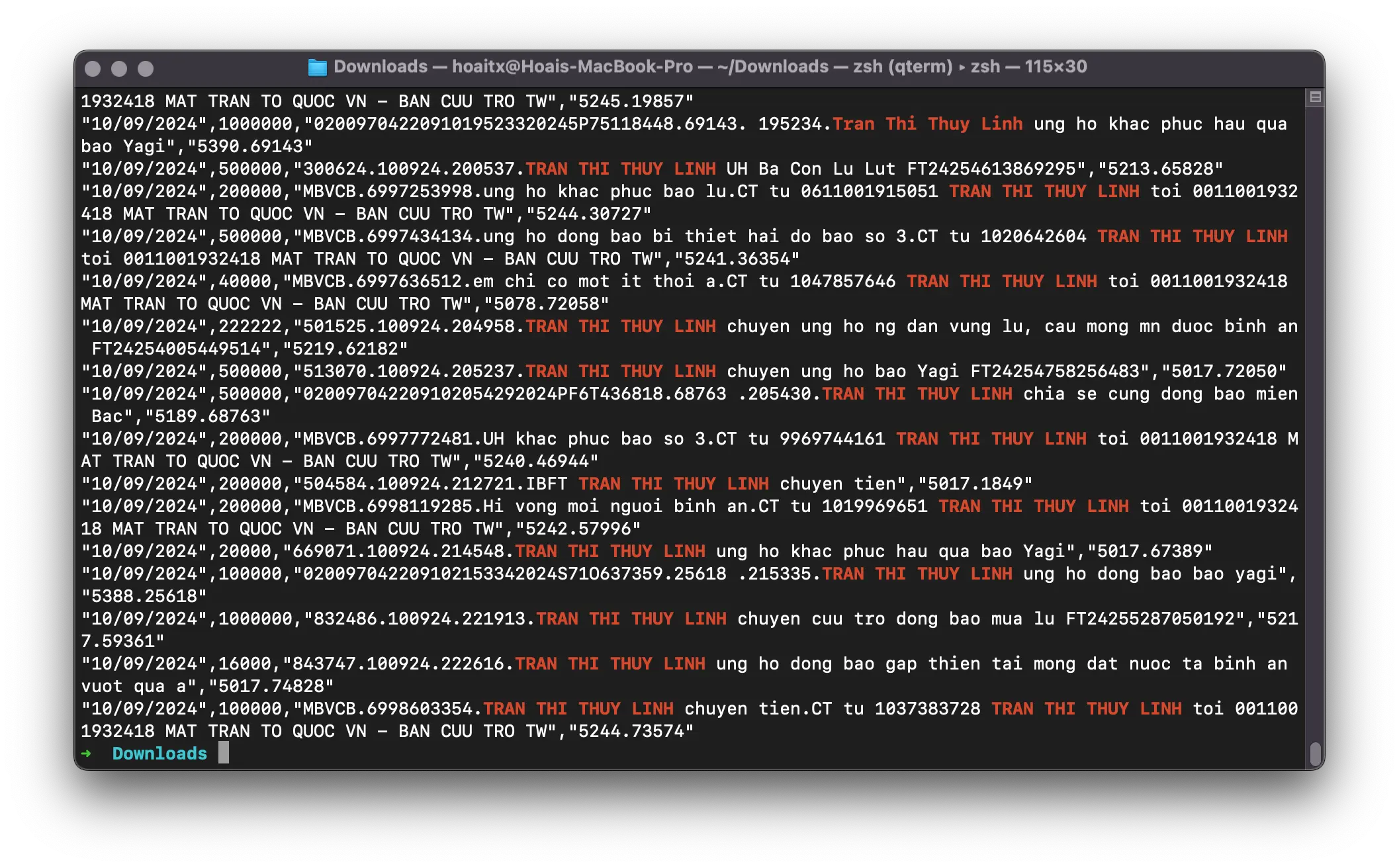
Tiếp theo đếm xem có bao nhiêu dòng sao kê:
$ awk '{count++} END {print count}' transactions.csv
Tuy nhiên số dòng trên là đang bao gồm cả dòng tiêu đề của csv, nên trừ đi 1 thì sẽ ra con số thực tế về số lượng giao dịch. Còn không thì hoàn toàn có thể xử lý bằng lệnh.
$ awk 'NR > 1 {count++} END {print count}' transactions.csv
awk là lệnh tổng hợp dữ liệu rất mạnh mẽ. Có thể coi nó như là một ngôn ngữ lập trình cho dữ liệu. Vì bạn có thể viết logic bên trong awk để thực hiện điều mà mình muốn.
Đếm tổng số tiền đã quyên góp được:
$ awk -F, 'NR > 1 {sum += $2} END {print sum}' transactions.csv
Đếm tổng số tiền ủng hộ được trong ngày 10/09/2024:
$ grep "10/09/2024" transactions.csv | awk -F, '{sum += $2} END {print sum}'
Một trong những điểm mình yêu thích ở các lệnh trong Linux là tính "pipe line", nghĩa là đầu ra của lệnh này sẽ thành đầu vào của lệnh khác. Sắp xếp, kết nối các lệnh lại với nhau sẽ tạo ra được quá trình xử lý xuyên xuốt.
Sắp xếp lại danh sách giao dịch theo số tiền giảm dần, nhưng chỉ trả về 100 dòng đầu tiên cho dễ quan sát.
$ sort -t, -k2 -nr transactions.csv | head -n 100
Đảo ngược kết quả.
$ sort -t, -k2 -n transactions.csv | head -n 100
Chèn thêm một cột số thứ tự vào nội dung sao kê.
$ awk 'NR==1 {print "\"STT\"," $0} NR>1 {print NR-1 "," $0}' transactions.csv | head -n10
Chèn thêm một cột số tài khoản ở cuối, số tài khoản của người chuyển khoản được trích xuất trong nội dung chuyển khoản (nếu có).
$ awk -F, '
BEGIN {OFS=","}
NR==1 {print "STT," $0 ",\"STK\""; next}
{
match($3, /tu ([0-9]{7,})/, m)
account_number = (RSTART > 0) ? m[1] : ""
print NR-1, $0, account_number
}' transactions.csv
Và còn nhiều ví dụ khác nữa. Hãy đọc tài liệu hoặc nhờ ChatGPT viết lệnh cho mong muốn của bạn.
Trên đây là một số ví dụ mà mình đã dùng để truy xuất một vài thông tin để thoả mãn tính tò mò. Đặc biệt muốn nhấn mạnh vào sức mạnh của các câu lệnh xử lý dữ liệu trong Linux. Chúng ta có thể kết hợp các lệnh đó lại với nhau để tìm kiếm thông tin mà mình mong muốn.