
Sử dụng gpt-4 miễn phí thông qua Github Models (có giới hạn)
Vấn đề
Là một người dùng mạng xã hội, không khó để nhìn thấy những bài viết có nội dung hỏi về việc có ai muốn dùng chung tài khoản ChatGPT Plus hay không. Đăng ký phiên bản Plus, bạn sẽ được dùng các mô hình mới nhất, mạnh mẽ nhất, tiêu biểu như là gpt-4, gpt-4o hay là o1-preview... Điều đó cho thấy nhu cầu sử dụng các mô hình này là rất lớn. Nhiều người dùng để phục vụ cho mục đích nghiên cứu, học tập. Hay chỉ đơn thuần là trải nghiệm cảm giác mới, xem chúng có gì nổi trội hơn những cái đã biết.
Với cái giá 20$ một tháng, tôi tin chắc rằng nhiều người sẽ e dè. Chúng ta có quá nhiều hoá đơn phải chi trả trong một tháng, có nhiều thứ quan trọng hơn cần phải chi tiêu. Vì vậy nếu có ai đó sẵn sàng "góp gạo thổi cơm chung" thì còn gì bằng, chi phí sẽ giảm đi theo "cấp số chia". Nếu có 5 người cùng dùng thì mỗi người chỉ cần trả 4$. Nhưng cũng vì thế mà lại tạo ra nhiều vấn đề mới. ChatGPT ở hiện tại đang giới hạn số lượng câu hỏi trong một khoảng thời gian nhất định. Vì vậy nếu như có ai đó "lỡ tay" dùng hết lượt thì người dùng sau phải chờ cho đến khi giới hạn được mở. Chưa kể những rủi ro về tiền bạc khi mua chung với những người lạ mặt. Vì vậy tốt hơn hết là chỉ nên mua với những người quen biết.
Trước đây tôi đã viết một bài về cách dùng gpt-4 miễn phí thông qua Github Copilot. Nhưng suy cho cùng thì đây cũng chỉ là một "trick" không chính thống, và đã cảnh báo đến bạn đọc rằng có nguy cơ tài khoản Copilot bị ăn "gậy". Cho đến giờ thì không chắc cách này còn hoạt động nữa hay không, nhưng bạn đọc không nên làm theo nữa. Bởi theo thống kê, bài viết đó đến giờ vẫn còn nhiều người đọc. Chà! Sức hút của gpt-4 ghê ghớm nhỉ!
Nhân dịp Github vừa mới public preview Github Models cho những ai có tài khoản Github đều truy cập được vào Models của họ. Bao gồm nhiều mô hình của gpt và nhiều mô hình nổi tiếng khác nữa, như Llama, Mistral... Bài viết này tôi sẽ hướng dẫn mọi người cách dùng miễn phí gpt-4 giống với ChatGPT nhất có thể. Và dĩ nhiên nó không xịn bằng hàng chính chủ, có nhiều hạn chế đi kèm, nhưng vẫn rất đáng để trải nghiệm.
Github Models
Github Models là tính năng mà Github hỗ trợ các lập trình viên sử dụng miễn phí các mô hình ngôn ngữ lớn (LLMs) cho mục đích thử nghiệm - theo họ nói. Sau khi hoàn tất, người dùng phải triển khai ứng dụng của họ với các nhà cung cấp khác bởi vì mô hình thử nghiệm bị rất nhiều hạn chế về tốc độ cũng như ngữ cảnh. Tuy nhiên nếu chỉ đơn thuần dùng cho mục đích cá nhân thì chấp nhận được.
Chúng ta đều biết trang web ChatGPT là dành cho tất cả mọi người - đặc biệt là người dùng miễn phí - trò chuyện với gpt-4o, 4o-mini... Sau một vài lượt trao đổi, bạn sẽ hết lượt và bị "giáng" xuống mô hình gpt-3.5. ChatGPT lưu lại lịch sử các cuộc trao đổi, từ đó giúp người dùng xem lại các cuộc trò chuyện. Đây cũng cách dễ nhất cho người dùng tương tác với các mô hình gpt.
Nếu không phải là lập trình viên, hoặc cũng có thể là lập trình viên nhưng mà không để ý, thì OpenAI - tức Công ty đứng sau ChatGPT cung cấp API để tương tác với các mô hình của họ. Hiểu đơn giản là thay vì sử dụng web chat thì bạn hoàn toàn có thể gọi API để làm được điều tương tự. Ví dụ một cuộc trò chuyện trong API sẽ trông như thế này:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
},
{
"role": "assistant",
"content": "Hi there! How can I assist you today?"
},
{
"role": "user",
"content": "What is the capital of Vietnam?"
}
]
}'
Bạn sẽ thấy rằng một cuộc gọi API bao hàm tất cả nội dung của cuộc hội thoại. Tức là để tiếp tục cuộc trò chuyện cần phải gửi lại toàn bộ nội dung giữa bạn và gpt trước đó. Giải thích rằng đó là ngữ cảnh của cuộc trò chuyện. gpt không lưu trữ trạng thái cho nên cách tốt nhất để cho nó hiểu nội dung cả hai đang trò chuyện là gửi lại toàn bộ nội dung trước đó.
Điều đặc biệt là bằng cách gọi API, bạn hoàn toàn có thể sử dụng được các mô hình mới nhất mà không nhất thiết phải đăng ký gói GPT Plus 20$ hàng tháng. Tuy nhiên, các cuộc gọi API là mất tiền và cách tính tiền cũng rất khác so với phiên bản web. Bạn phải trả tiền nhiều hơn nếu gọi API nhiều hơn và nội dung cuộc trò chuyện dài cũng sẽ tốn nhiều chi phí, vì API tính tiền dựa trên tokens đầu vào/ra. Chưa kể, chi phí vào/ra là khác nhau, phụ thuộc vào model mà bạn sử dụng nữa.
"Chà, nhức cái đầu thật. Chỉ mỗi việc tính tiền thôi mà đã phức tạp như vậy rồi thì đăng ký Plus đi cho khoẻ 😆". Chắc đọc đến đây nhiều người sẽ nghĩ như vậy, nhưng cũng đúng thôi! Bạn bỏ tiền ra để mua sự hài lòng, đó mới là đỉnh cao của nghệ thuật bán hàng. Còn nếu dành ra một ít thời gian mà lại được dùng miễn phí thì buộc chúng ta phải đọc và vọc vạch nhiều hơn nữa.
Dưới đây là bảng giá theo tokens in/out cho mô hình gpt-4o mini.
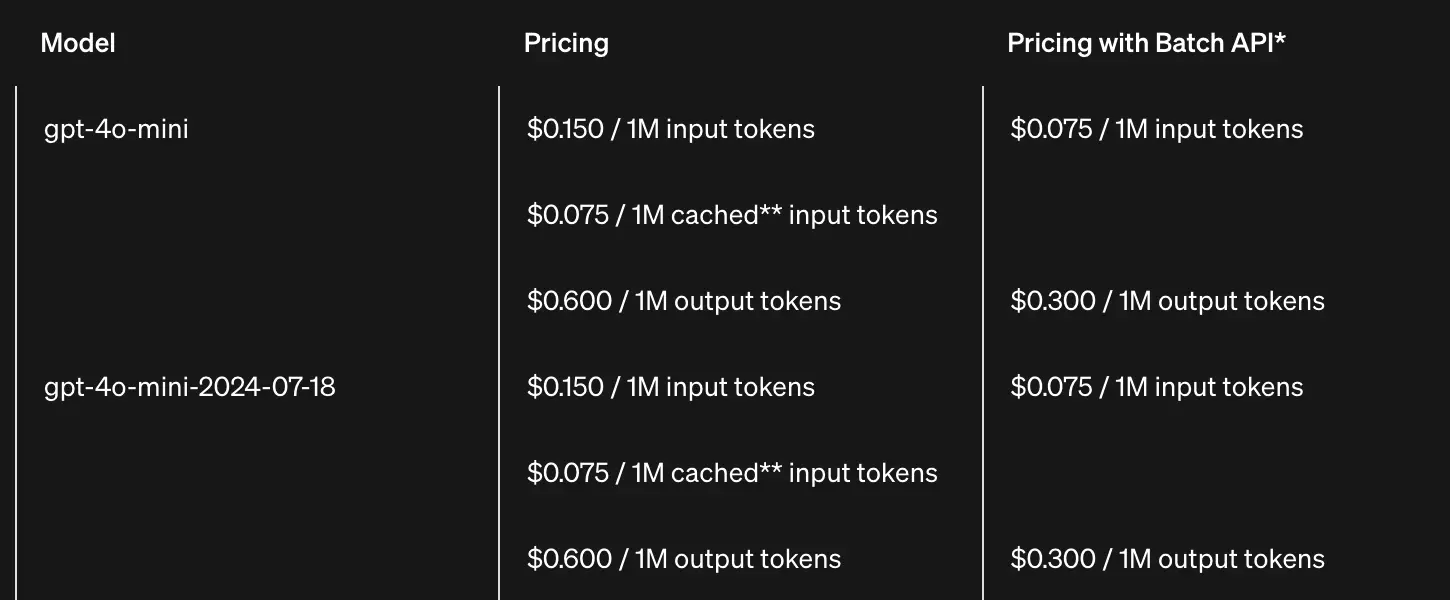
Input tokens là số lượng ký tự gửi lên, trong khi Output tokens là số lượng ký tự mà model phản hồi. Tức là bạn gửi lên càng nhiều hoặc models phản hồi lại càng nhiều thì số tiền bỏ ra càng lớn. Tokens được tính toán dựa trên một vài nguyên tắc, về cơ bản bạn có thể xem nó gần tương đương với từ (words) (1 token = 3/4 word), tức là 3 từ sẽ tương ứng với 3 tokens. Công thức chuẩn hơn xem tại Tokenizer | OpenAI Platform.
Sau khi đăng ký tài khoản tại Github, truy cập vào Marketplace Models bạn sẽ thấy danh sách mô hình được phép sử dụng. Bấm vào mô hình bất kỳ, giả sử ở đây là OpenAI GPT-4o mini. Bấm vào nút Playground ở phía trên màn hình bên tay phải. Tại đây bạn sẽ thấy giao diện Chat gần giống với ChatGPT. Hãy thử bắt đầu trò chuyện như bình thường. Chúc mừng, bạn đang sử dụng gpt-4o mini miễn phí.
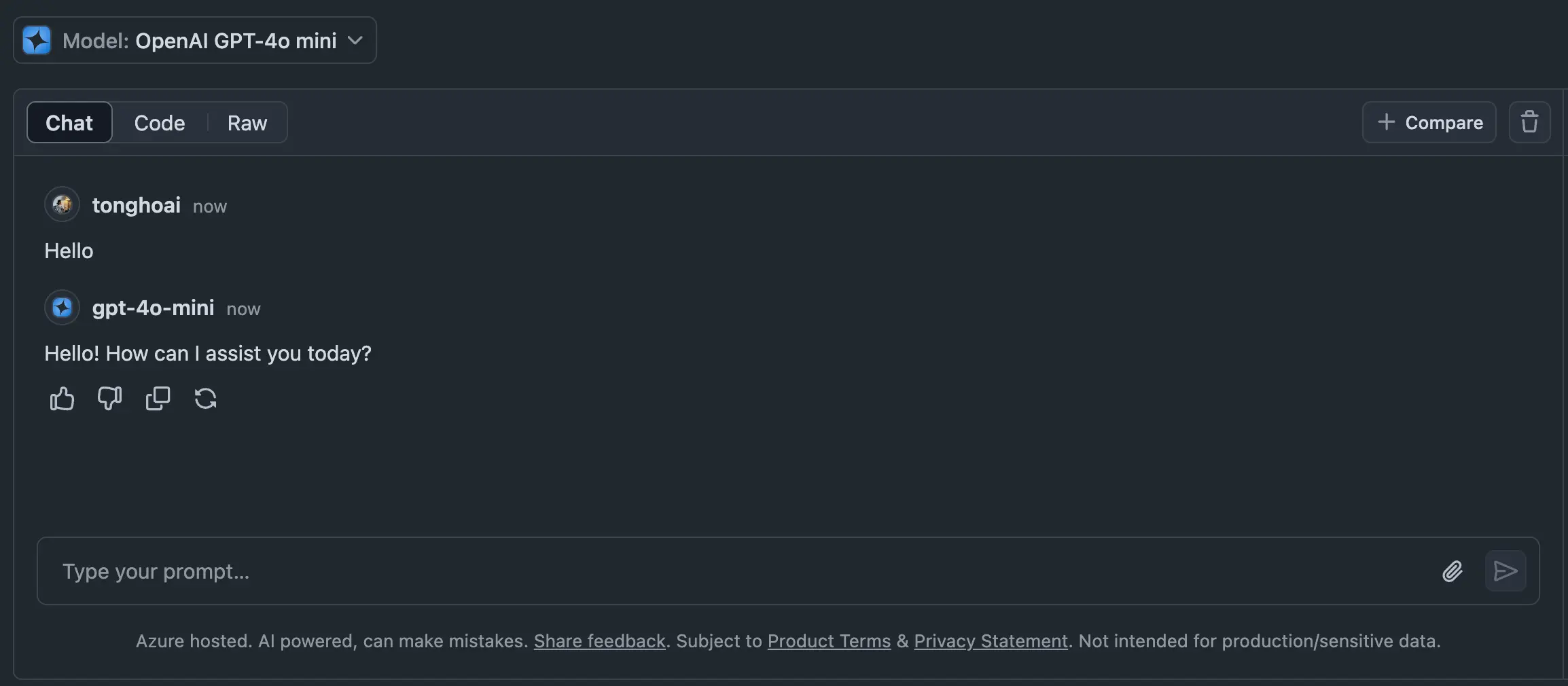
Nhưng cách dùng này hơi bất tiện vì nó không lưu lại được lịch sử cuộc trò chuyện, cũng như giao diện không thân thiện cho lắm. Ngay sau đây, tôi sẽ hướng dẫn cho bạn một cách khác "chuyên nghiệp" hơn nhiều.
Lobe Chat
Lobe Chat là một dự án mã nguồn mở, cung cấp giao diện và tính năng để tương tác với các mô hình ngôn ngữ lớn. Hiểu đơn giản Lobe Chat cung cấp giao diện Chat giống như ChatGPT.
Lobe Chat giúp chúng ta quản lý được các cuộc trò chuyện. Ngoài ra nó còn cố gắng tích hợp thêm rất nhiều tính năng khác nữa nhưng trong phạm vi bài viết này tạm thời tôi sẽ chưa nhắc đến. Lobe Chat tương tác với LLMs thông qua API cho nên bạn cần cấu hình kết nối cho các cuộc gọi đến máy chủ của model tương ứng. Ở đây tôi sẽ hướng dẫn bạn cấu hình cho Github Models.
Trước tiên, cần lấy được Github Tokens để làm cơ bản cho xác thực. Truy cập vào Personal access tokens | Github. Bấm vào "Generate new token (classic)". Nhập tên tokens và chọn thời gian hết hạn của tokens tuỳ ý muốn. Không cần chọn scopes nào cũng được. Bấm vào Generate token ở phía cuối cùng và lưu lại mã tokens vừa nhận được.
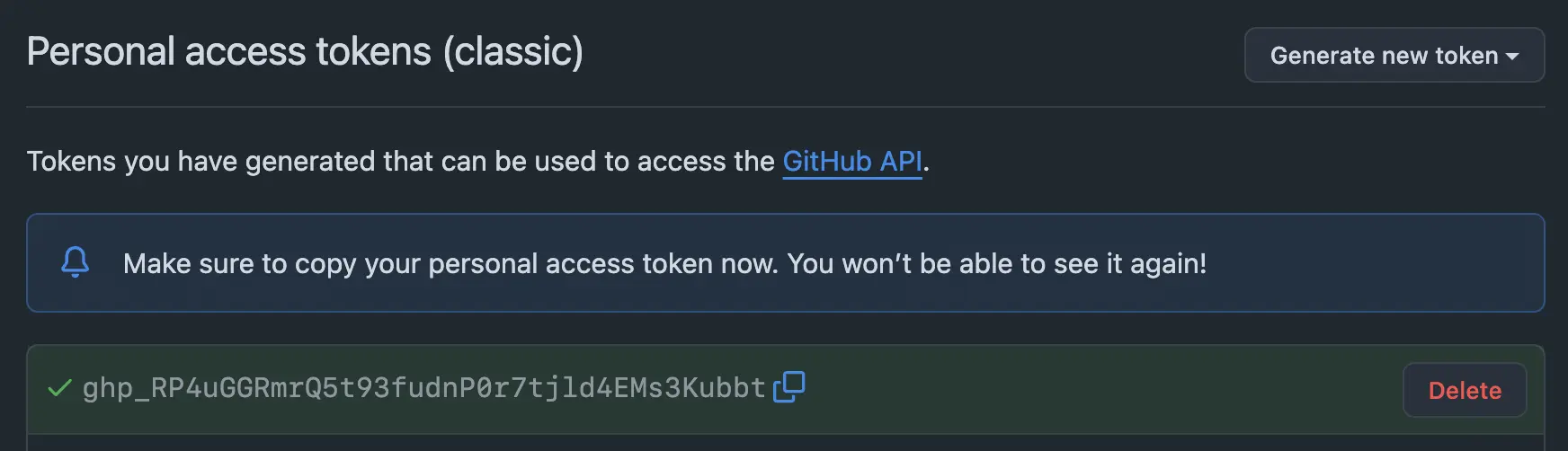
Tiếp theo, cài đặt Lobe Chat vào máy tính. Bạn có thể triển khai Lobe Chat lên rất nhiều dịch vụ đám mây như Vercel, Zeabur... chỉ bằng 1 nút bấm vì Lobe là một ứng dụng trên nền Web. Hoặc nếu dùng Docker, chỉ cần chạy một lệnh.
$ docker run -d -p 3210:3210 --name lobe-chat lobehub/lobe-chat
Truy cập vào http://localhost:3210 sẽ thấy giao diện của Lobe Chat. Tiếp theo chúng ta cần thiết lập cấu hình API để cho nó hoạt động.
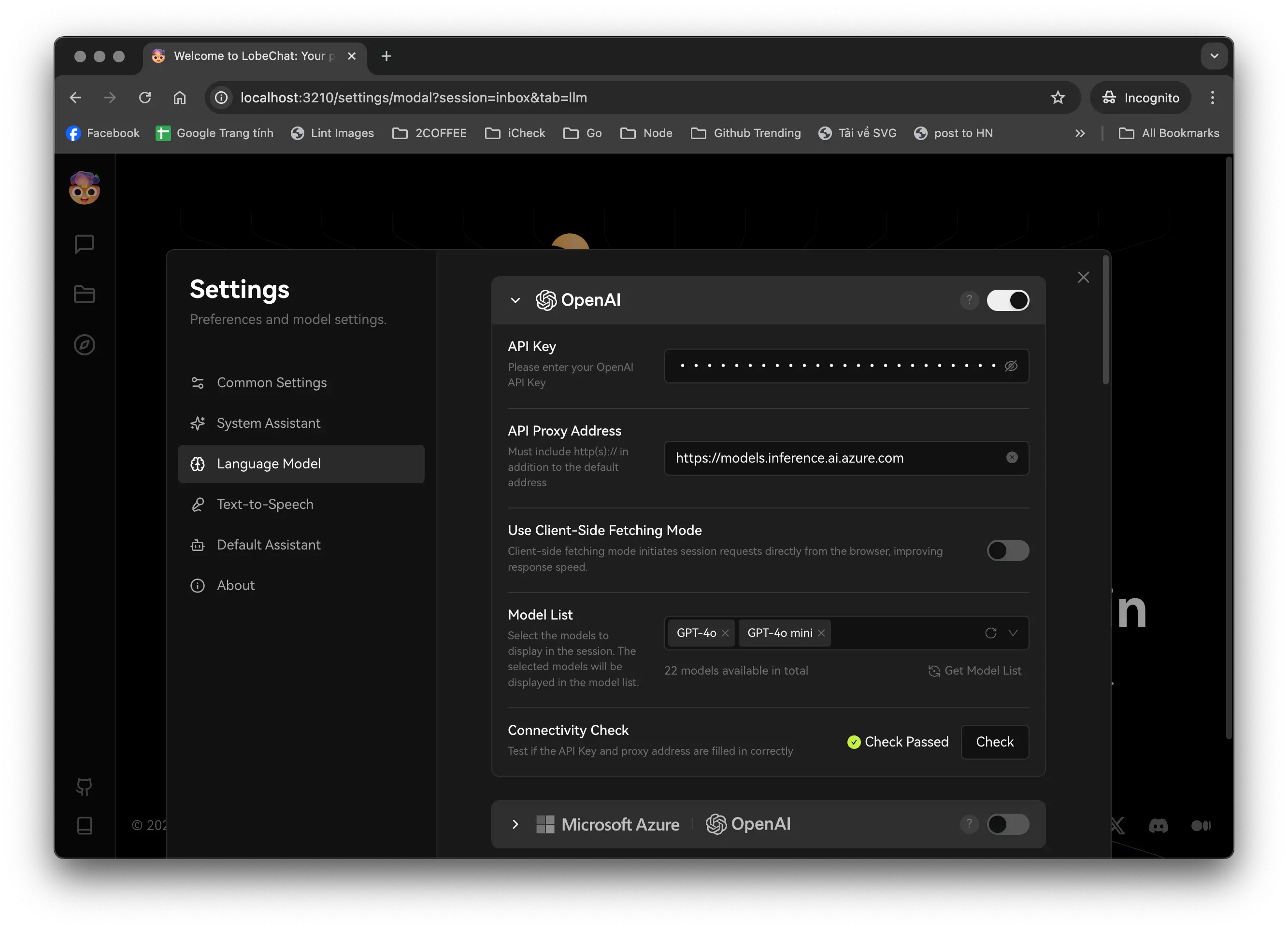
Bấm vào avatar Lobe Chat ở phía trên bên trái, chọn "Settings", bấm vào tab "Language Model" bạn sẽ thấy màn hình cài đặt OpenAI. Cần điền vào "API Key", "API Proxy Address" và "Model List". API Key chính là Github tokens vừa tạo ở phía trên, API Proxy Address ở thời điểm viết bài, nó là:
https://models.inference.ai.azure.com
Tại ô "Model List", nhập vào danh sách các models muốn dùng. Để biết được chính xác tên của model, bạn truy cập vào từng model trên Github Models, nhấn vào Playground, chuyển sang tab "Code". Ví dụ ở đây tôi nhập vào "gpt-4o", "gpt-4o-mini". Bấm vào nút "Check" để kiểm tra lại cấu hình chuẩn hay chưa. Nếu hiện "Check Passed" là đã thành công.
Bây giờ hãy thử tạo một cuộc trò chuyện mới.
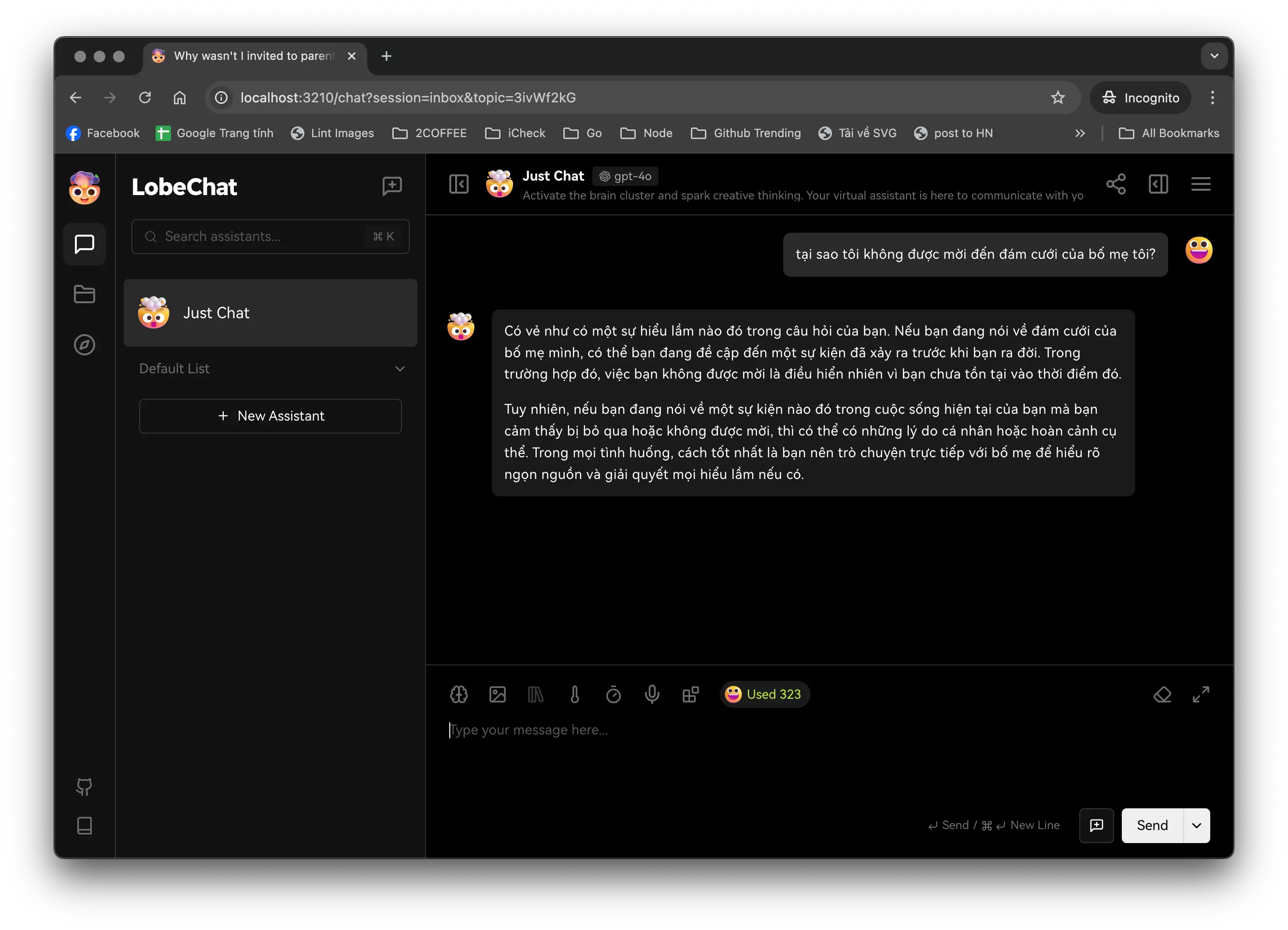
Tuyệt vời!
Hạn chế
Có một vài hạn chế đáng lưu ý mà bạn cần biết trong khi sử dụng.
Đầu tiên là hạn chế về tốc độ trò chuyện và giới hạn số lượng gọi API trong ngày. Github gán nhãn cho từng mô hình để xác định những hạn chế đó. Ví dụ nhìn vào bảng dưới đây.
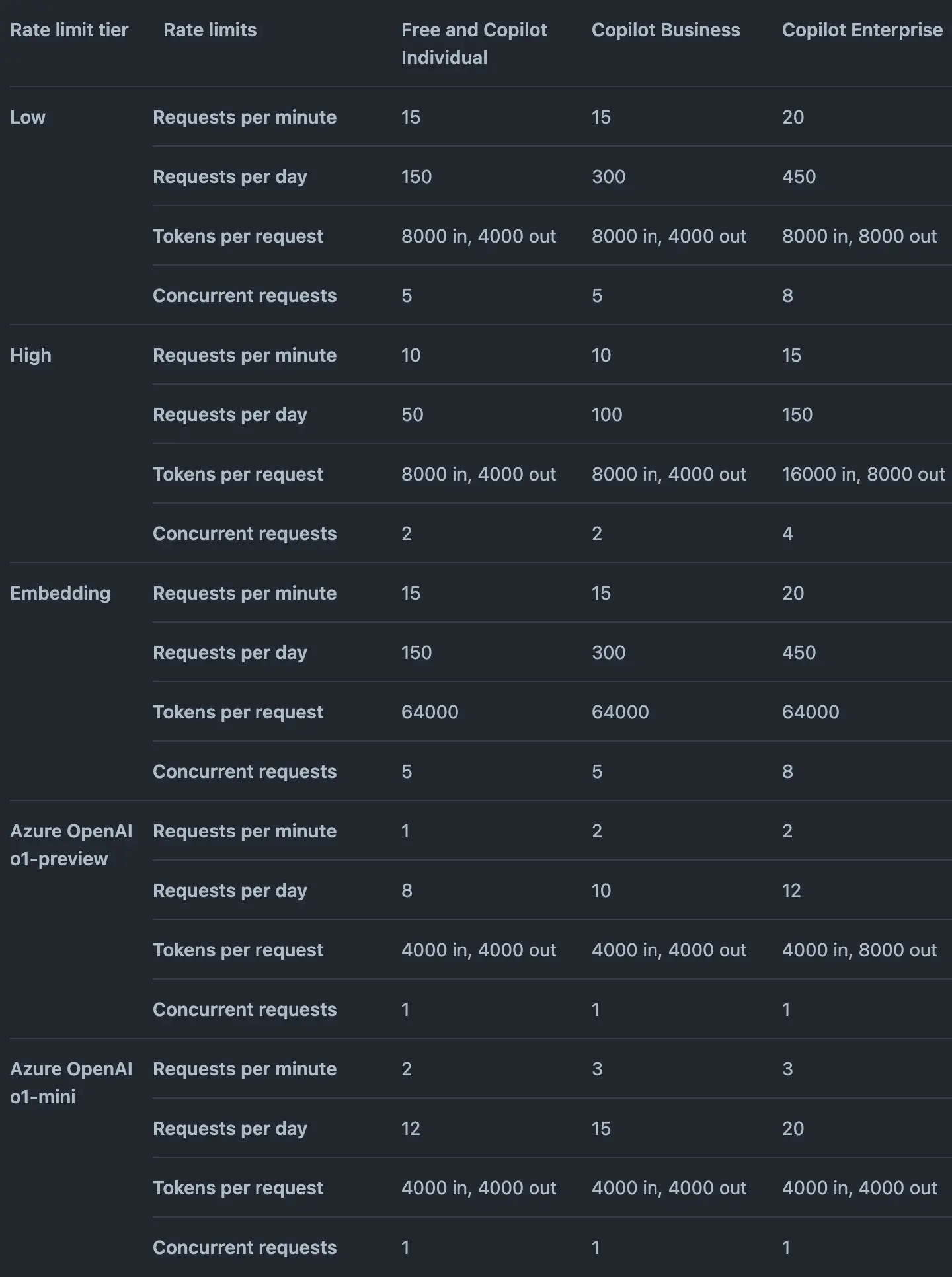
Các nhãn này nằm trong màn chi tiết của mô hình. Ví dụ đối với gpt-4o được gắn nhãn "High", đồng nghĩa với việc trong một ngày bạn chỉ được gọi 50 requests - tương tương với 50 câu hỏi, và bị giới hạn 10 requests mỗi phút cũng như chỉ được gọi tối đa 2 requests đồng thời.
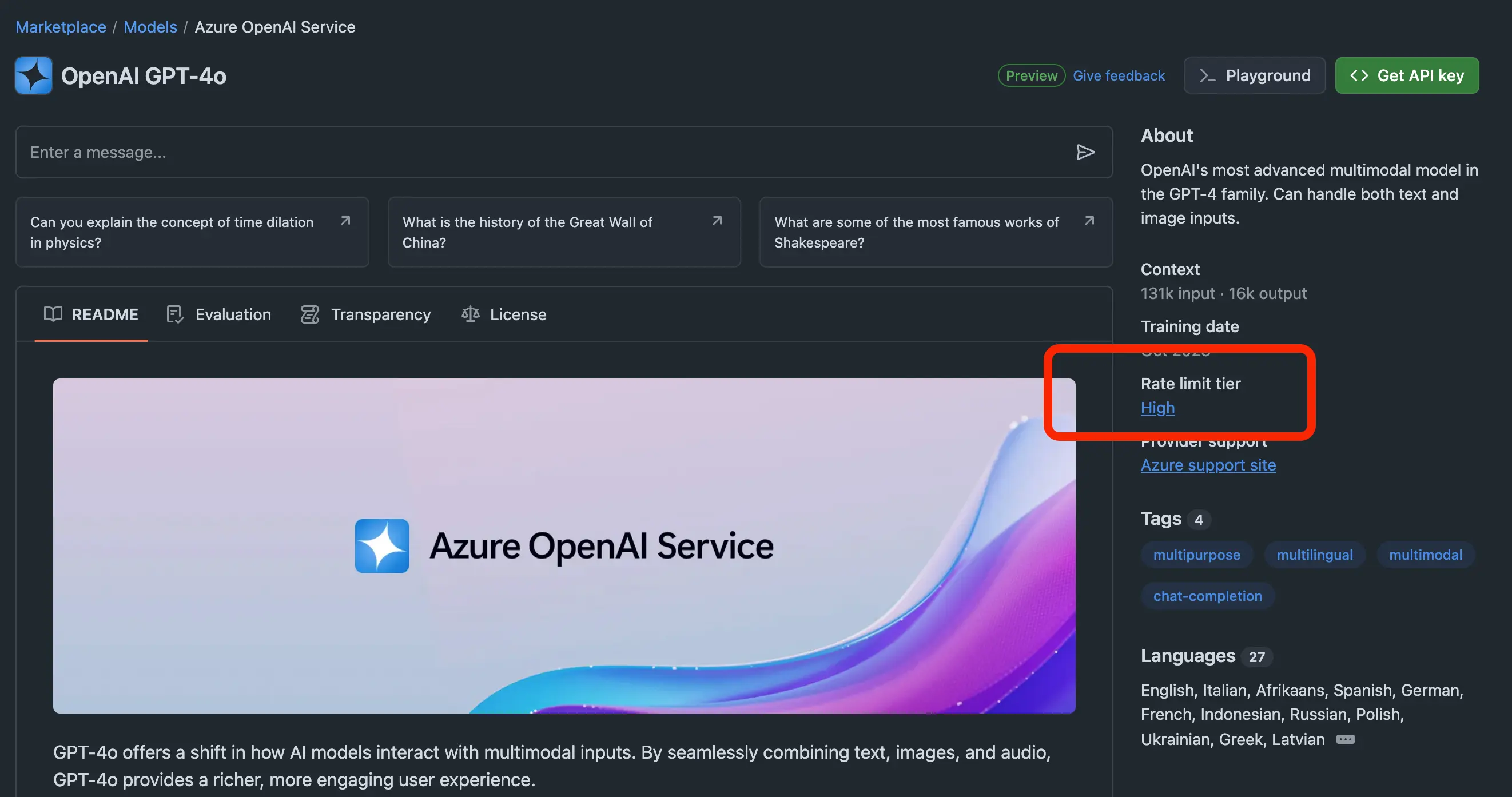
Ngoài ra hãy để ý thêm mục "Tokens per request" là lượng tokens in/out cho mỗi request. Ví dụ với gpt-4o là "8000 in, 4000 out", tức là số lượng từ gửi lên tối đa là 8000 từ, số lượng từ mà model phản hồi chỉ đạt tối đa là 4000. Trong khi gpt-4o hỗ trợ tokens in/out lên đến 131k input, 16k output. Rõ ràng là đang bị hạn chế quá nhiều. Hy vọng trong tương lai Github sẽ "cơi nới" thêm giới hạn này.
Bạn cũng chưa thể tạo hình ảnh hay audio. Lobe Chat chỉ lưu trữ các cuộc hội thoại dưới máy tính nên bạn chỉ có thể xem lại cuộc hội thoại đã tạo trên máy. Hoặc chuyển sang cấu hình trên dịch vụ đám mây.
Mặc dù vẫn còn nhiều hạn chế tuy nhiên đối với những ai đang muốn trải nghiệm hoặc dùng với tần suất ít thì đây là giải pháp "cứu cánh". Nếu dùng hết giới hạn của model này bạn có thể chuyển sang mô hình khác để tiếp tục sử dụng. Ngoài gpt ra thì vẫn còn rất nhiều mô hình mạnh mẽ khác chờ bạn khám phá.
Bạn có thấy cách dùng này thú vị không hoặc bạn có cách nào muốn chia sẻ không thì hãy để lại bình luận xuống phía dưới bài viết nhé. Xin cảm ơn.