
Redisearch là gì? 2coffee.dev đang sử dụng redisearch làm cơ sở dữ liệu!
Vấn đề
Cơ sở dữ liệu là một phần không thể thiếu đối với các trang web hiện nay. Hầu hết chúng ta đều nghe qua hai trường phái là SQL và NoSQL. Mỗi bên đều có điểm mạnh - yếu riêng, tùy thuộc vào nhu cầu sử dụng mà lựa chọn sao cho hợp lý. Redis là một dạng NoSQL, thường được biết đến trong mục đích sử dụng cho việc cache dữ liệu.
Cho các bạn chưa biết trang blog của tôi đang sử dụng redisearch làm cơ sở dữ liệu. Redisearch là một module của redis. Trước khi đến với redisearch, tôi từng sử dụng mysql. Nhưng tại sao? Chuyển qua redisearch có khó khăn gì không và cách dùng redisearch có dễ không?... Hãy cũng tôi khám phá trong bài viết này nhé!
Redisearch là gì?
Redisearch là một module của redis cung cấp khả năng truy vấn, lập chỉ mục và khả năng tìm kiếm full-text mạnh mẽ. Bạn biết lệnh LIKE trong SQL chứ? Nó dùng để tìm kiếm dữ liệu phù hợp với một chuỗi tìm kiếm. LIKE có nhiều hạn chế trong SQL như tốc độ tìm kiếm trên tập dữ liệu lớn là không cao, hơn nữa với các loại tìm kiếm phức tạp như lỗi chính tả, gợi ý cụm từ... thì khó có thể mà làm được tốt hơn Redisearch.
Redisearch sử dụng "inverted indexes" cùng với "compressed" cho phép lập chỉ mục một cách nhanh chóng với chi phí bộ nhớ thấp. "inverted indexes" là loại chỉ mục lưu trữ ánh xạ từ nội dung, chẳng hạn như từ hoặc số, đến vị trí của nó trong bảng hoặc trong tài liệu hoặc một bộ tài liệu. Mục đích của nó là cho phép tìm kiếm "toàn văn bản" nhanh chóng. Cùng với công nghệ "compressed" của họ để giảm chi phí lưu trữ.
Nếu như trước đây bạn đã từng sử dụng redis phục vụ cho việc cache dữ liệu thì giờ đây redisearch được sinh ra vừa kế thừa được tốc độ, đồng thời cung cấp khả năng truy vấn cực kì mạnh mẽ.
Tại sao tôi lựa chọn redisearch?
Đặc thù của một trang blog là đọc dữ liệu nhiều hơn việc ghi, vì thế tôi luôn ưu tiên cho việc lấy dữ liệu ra làm sao cho nó nhanh chóng và chính xác nhất. Đồng thời với một cấu hình server khiêm tốn chỉ 1CPU 1GB RAM thì càng phải tối ưu bộ nhớ và tốc độ xử lý cho hệ thống.
Như đã nói ở trên trước khi tôi có sử dụng mysql. Nói về độ ổn định thì mysql cho tính ổn định rất cao, khả năng truy vấn dữ liệu cũng rất tốt. Có điều nó sử dụng tương đối nhiều bộ nhớ, kèm theo đó khả năng tìm kiếm full-text chưa được mạnh mẽ khi tôi yêu cầu chức năng tìm kiếm là chủ lực cho blog.
Redisearch thì tôi nghe danh đã lâu nhưng chưa có cơ hội tìm hiểu, sẵn tiện đang đi tìm giải pháp cho vấn đề trên thì tôi có bắt tay vào nghiên cứu luôn xem có thể áp dụng vào dự án được không. Thì quả nhiên không nằm ngoài mong đợi, redisearch hoàn toàn đáp ứng được.
Thoạt đầu tôi chỉ dự định dùng thêm redisearch như một cơ sở dữ liệu thứ 2 chỉ dành cho việc tìm kiếm full-text, nhưng sau đó tôi phát hiện ra so với redis thì redisearch còn đáp ứng được cả khả năng lưu trữ lẫn truy xuất dữ liệu, hoàn toàn có thể thay thế mysql.
Redisearch đang trong quá trình hoàn thiện để đón nhận nhiều hơn từ phía cộng đồng. Vì thế các vấn đề phát sinh trong quá trình di chuyển từ mysql sang redisearch lúc đầu cũng gặp nhiều khó khăn. Song, tài liệu trên trang chủ của redisearch khá là đầy đủ nên hầu hết các vấn đề mà tôi gặp phải đều được giải quyết.
Sử dụng redisearch như thế nào?
Cài đặt redisearch
Việc đầu tiên bạn cần làm là cài đặt redisearch. Có nhiều cách để cài đặt redisearch như cài qua docker, thông qua bộ cài đặt hoặc build from source.
Để cài đặt qua docker bạn dùng lệnh:
docker run -p 6379:6379 redislabs/redisearch:latest
Hoặc bạn có thể xem tất cả các cách khác ở Quick Start Guide for RediSearch.
Tạo một index
Chúng ta cần tạo một index trước khi sử dụng nó để tìm kiếm. Index đóng vai trò cho việc lập chỉ mục và tìm kiếm.
Sử dụng lệnh FT.CREATE để tạo một index.
Ví dụ tôi tạo một index có tên là article lưu trữ các bài viết:
FT.CREATE article ON HASH PREFIX 1 article: SCHEMA url TAG SEPARATOR "," title TEXT content WEIGHT 5.0 TEXT created_at NUMERIC SORTABLE
Index article được lưu trữ trong kiểu dữ liệu HASH có key bắt đầu bằng article gồm có các trường dữ liệu: url có kiểu TAG, title và content có kiểu dữ liệu là TEXT và created_at là NUMERIC để lưu ngày tạo bài viết dạng unix timestamp.
Redisearch hỗ trợ kiểu dữ liệu trong các field gồm có TEXT, NUMERIC và TAG, các TAG có thể liên tưởng nó như là các khóa chính (Primary Keys) trong các cơ sở dữ liệu SQL.
Đặt WEIGHT để xác định tầm quan trọng của field, WEIGHT càng cao thì khi tìm kiếm sẽ càng được ưu tiên. Ngoài ra nếu muốn dữ liệu được sắp xếp trong khi truy vấn thì phải khai báo thêm SORTABLE.
Thêm dữ liệu vào index
HSET article:1 url "hello-word" title "hello world" content "lorem ipsum" created_at 1630245601
HSET article:2 url "hello-word-2" title "hello world 2" content "lorem ipsum 2" created_at 1630245602
HSET article:3 url "hello-word-3" title "hello world 3" content "lorem ipsum 3" created_at 1630245603
Query
Redisearch cung cấp cơ chế tìm kiếm theo các trường dữ liệu, chúng ta có thể tìm kiếm chính xác, tìm kiếm các từ, cụm từ với sự kết hợp của các phép OR, AND, NOT... trong câu truy vấn.
Xem tất cả cú pháp mà Redisearch hỗ trợ tìm kiếm tại Search Query Syntax .
Để query theo trường dữ liệu, sử dụng cú pháp @field kèm theo phía sau là dữ liệu cần tìm kiếm. Ví dụ:
Tìm kiếm chính xác theo url:
FT.SEARCH article @url:{ hello-world }
Tìm kiếm full-text cụm từ hello world:
FT.SEARCH article @url:"hello world"
Tìm kiếm bài viết có created_at lớn hơn 1630245602:
FT.SEARCH article @created_at:[(1630245602 inf]
Lấy ra tất cả bài viết và sắp xếp theo created_at giảm dần:
FT.SEARCH article * SORTBY created_at DESC
Dữ liệu vào redisearch sẽ được phân tích và làm mịn theo một vài quy tắc. Ví dụ như các kí tự đặc biệt khi được đánh index sẽ bị bỏ qua nếu như chúng ta không can thiệp. Để hiểu rõ hơn về những quy tắc này bạn đọc xem tại Controlling Text Tokenization and Escaping .
Tốc độ
Về tốc độ lập chỉ mục và tìm kiếm, redisearch không hề thua kém bất kì công cụ hỗ trợ tìm kiếm nào khác như Elastic Search hay Solr. Thậm chí nó còn cho tốc độ đáng kinh ngạc.
Cụ thể trên trang blog của Redis, những người phát triển tiến hành so sánh hiệu năng của hai công cụ Redisearch & Elastic Search thông qua bài kiểm tra đánh index và tìm kiếm 5,6 triệu tài liệu lấy từ trang wikipedia.
Kết quả đánh index:
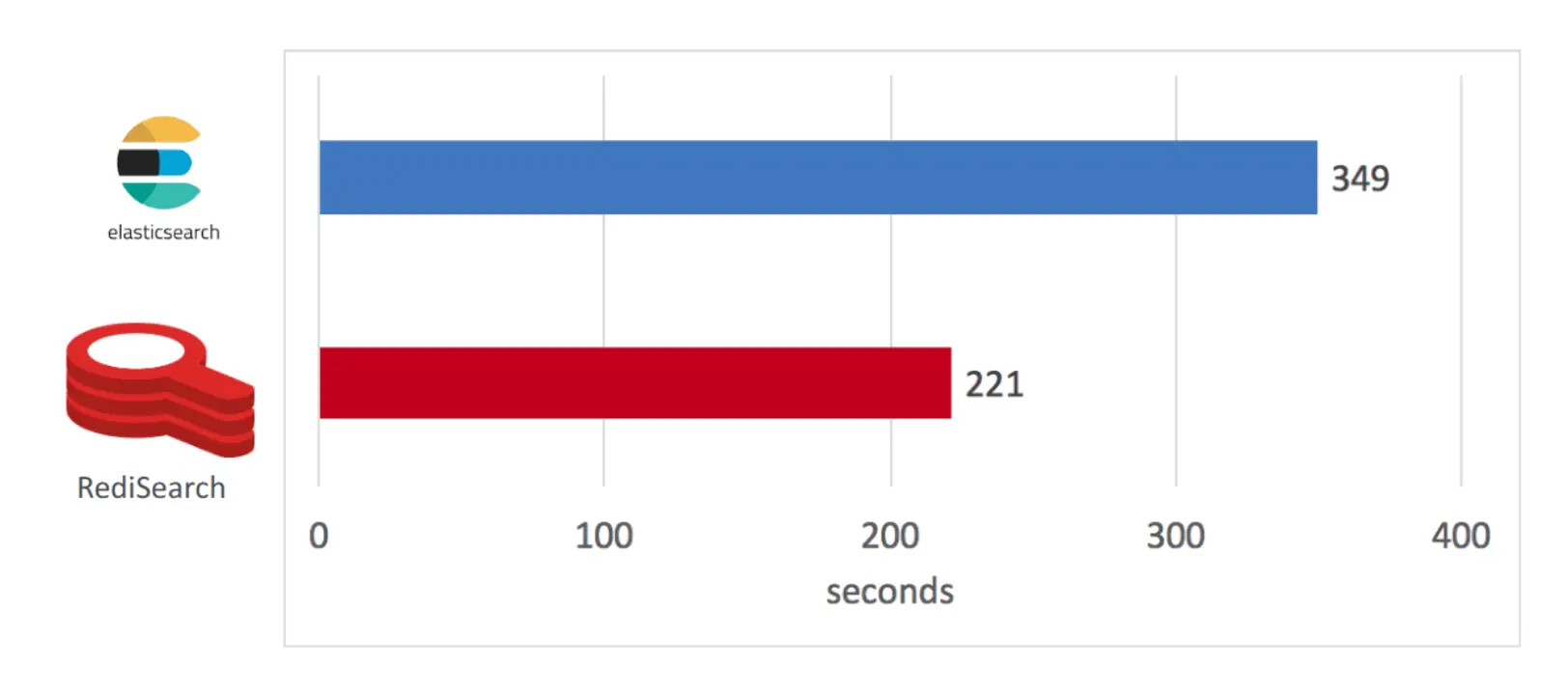
Kết quả tìm kiếm với hai từ khóa ngẫu nhiên:
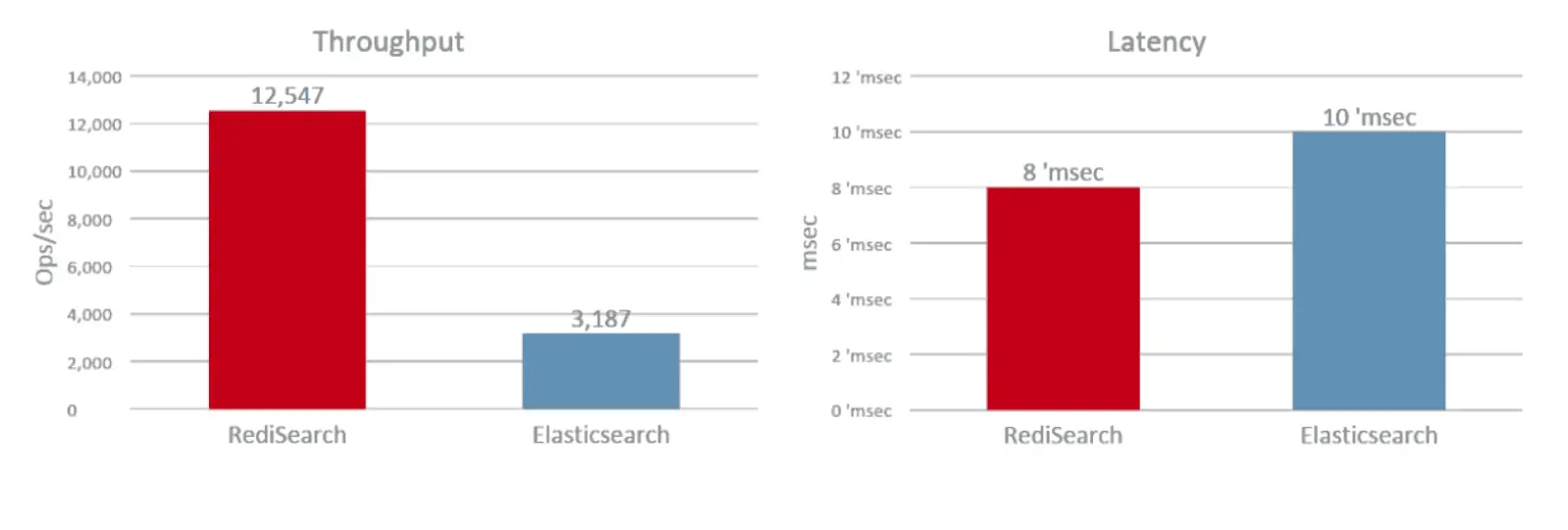
Nếu muốn tìm hiểu chi tiết hơn, bạn đọc thêm ở Search Benchmarking: RediSearch vs. Elasticsearch.
Tổng kết
Redisearch là một cơ sở dữ liệu hỗ trợ lập chỉ mục và tìm kiếm full-text cực kì mạnh mẽ với chi phí bộ nhớ được tối ưu. Tôi tình cờ tìm đến redisearch khi mà đang tìm kiếm một giải pháp tìm kiếm full-text thay thế cho Elastic Search vốn yêu cầu cấu hình máy chủ tương đối cao.
Redisearch hỗ trợ nhiều cú pháp tìm kiếm trên nhiều trường dữ liệu có trong một chỉ mục. Ngoài ra bạn còn có thể đặt trọng số cho tài liệu để tìm kiếm chính xác hơn, kết quả tìm kiếm cũng được đánh giá thông qua điểm tìm kiếm.
Về hiệu năng, redisearch không hề thua kém bất kì công cụ tìm kiếm nào khác như Elastic Search hay Solr.