
ChatGPT API cùng những vấn đề mới trong cuộc chiến với dịch thuật
Vấn đề
Cách đây 1-2 tuần, tôi có bài viết nói về quá trình tích hợp ChatGPT vào AdminCP để dịch bài viết từ Tiếng Việt sang Tiếng Anh phục vụ cho mục đích làm website đa ngôn ngữ. Mới đây ít hôm, ChatGPT đã chính thức cho người dùng Việt Nam đăng ký và sử dụng rộng rãi, đồng thời người dùng đã có thể mua được phiên bản Plus hoặc nạp tiền vào tài khoản để đáp ứng nhu cầu sử dụng API. Điều này đã kích thích trí tò mò của tôi.
Quay về hiện tại, tính năng dịch trong AdminCP đang hoạt động tương đối tốt, thi thoảng ChatGPT “đoảng trí" có dịch sai định dạng của tôi đi một chút, nhưng vấn đề đó không quá nghiêm trọng, chỉ mất thời gian xóa câu trả lời "hề hước" đó đi rồi yêu cầu lại. Như đã nói, ChatGPT đã cho phép người dùng Viêt Nam trả tiền sử dụng API, tôi cũng muốn thử xem cách nó hoạt động như thế nào, cũng như giá cả ra sao. Nếu như sau này có nhu cầu gì, thì sẽ có kinh nghiệm để triển khai.
Nghĩ là làm, cuối tuần vừa rồi tôi đã thử nghiệm API mới và thử tích hợp nó vào AdminCP như một phiên bản nâng cấp.
Vấn đề với thư viện cũ
Ở thư viện cũ, tức là transitive-bullshit/chatgpt-api, tôi sử dụng phương thức ChatGPTUnofficialProxyAPI để khởi tạo một phiên bản ChatGPT “không chính thức”. Bởi vì trước đó không sử dụng được API keys của OpenAI mà phải sử dụng Access Token để tương tác với ChatGPT. Hiểu đơn giản, sử dụng API Keys thì mới tương tác được với API, còn dùng Access Token giống như là đang sử dụng giao diện chat (UI) của nó ở địa chỉ chat.openai.com, có điều là ChatGPTUnofficialProxyAPI cần sử dụng một Proxy Server để chuyển tin nhắn của chúng ta đến UI, cho nên mới gọi là “unofficial”.
Việc tương tác với ChatGPT lúc này không khác gì phiên bản lúc đang nói chuyện với nó qua UI.
Trong thư viện cũng có phương thức ChatGPTAPI để tương tác với API "real" của ChatGPT. Sau khi tạo được API keys, tôi thử chuyển từ ChatGPTUnofficialProxyAPI sang ChatGPTAPI, vì theo tài liệu, các phương thức có trong hai lớp này tương đối giống nhau, cũng có sendMessage để bắt đầu việc gửi một tin nhắn nên tôi nghĩ quá trình chuyển đổi sẽ nhanh thôi.
Nhưng do không chọn ngày, hay đơn giản do mình đen hay sao mà không tài nào làm cho nó hoạt động được. Cụ thể sau khi khởi tạo ChatGPTAPI, gọi phương thức sendMessage nhưng phản hồi nhận lại được là một cái gì đó “lệch tông” hẳn với câu hỏi, tôi không nhớ chính xác câu trả lời nhận được là gì, nhưng đại ý là xin lỗi vì nó là một AI có dữ liệu cập nhật đến ngày XX và không thể trả lời câu hỏi này!?
const api = new ChatGPTAPI({ apiKey: process.env.OPENAI_API_KEY })
// send a message and wait for the response
let res = await api.sendMessage('What is OpenAI?')
console.log(res.text)
Để không tốn thêm thời gian, tôi tìm đến tài liệu của OpenAI tại API reference - OpenAI. Tại đây tìm thấy danh sách API dành cho cuộc hội thoại (chat) của ChatGPT và thư viện có tên openai chính chủ.
Đã đến lúc mình cần chuyển sang thư viện mới xem sao.
Vấn đề với thư viện mới
Chẳng có gì khó khăn để khởi tạo một ví dụ đơn giản cả, vì trên tài liệu đã có sẵn, tôi chỉ copy lại, thay thế API keys và xem nó có hoạt động không.
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: 'My API Key',
});
async function main() {
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: 'gpt-3.5-turbo',
});
}
Ồ, nó phản hồi như một ChatGPT thực thụ, điều đó có nghĩa mọi thứ đang hoạt động đúng như ý mình.
Nhớ lại triển khai trước đó, có 2 phương thức là sendMessage và sendNext tương ứng với hành động gửi tin nhắn và tiếp tục câu trả lời. Nếu như bạn sử dụng ChatGPT trên UI, khi câu trả lời quá dài, ChatGPT sẽ dừng lại, bạn cần bấm vào nút “Continue” để tiếp tục nhận được câu trả lời. Hai phương thức trên chỉ đơn giản là mô phỏng lại hành vi này.
Theo như dự định, tôi cũng triển khai lại 2 phương thức này. Nhưng tìm mãi không thấy có API nào để thực hiện hành vi “Continue”, Quái lạ, thế thì làm thế nào để nhắc ChatGPT tiếp tục câu trả lời nhỉ?
Nghĩ thế, tôi cứ viết phương thức gửi tin nhắn trước, sau đó gửi một tin nhắn yêu cầu nó dịch một bài viết hơn 1000 từ, quả không sai, sau khoảng một vài phút chờ đợi thì có phản hồi nhưng chưa đầy đủ, tôi tiếp tục gửi một tin nhắn ngay sau đó với đại ý là yêu cầu tiếp tục câu trả lời thì nó không hiểu tôi đang muốn gì. Lúc này nhiều điểm bất thường bắt đầu xuất hiện như conversation ID, parent ID… hay nói cách khác là ngữ cảnh trước đó gửi vào đâu để ChatGPT có thể hiểu được nội dung cuộc trò chuyện?
Lang thang tìm câu trả lời, cuối cùng cũng biết cách để truyền đạt lại ngữ cảnh cho nó hiểu. Nếu như bạn trò chuyện với ChatGPT trên UI, nó sẽ phân ra thành các cuộc hội thoại với đầy đủ nội dung trò chuyện. Vì thế nếu bạn tiếp tục nói chuyện, nó vẫn hiểu được ngữ cảnh trước đó để trả lời chính xác. Nhưng các cuộc gọi trực tiếp đến API thì lại khác, không có tin nhắn nào được lưu lại, không có ngữ cảnh để hiểu cho nên muốn ChatGPT hiểu được bối cảnh bạn đang tạo ra thì phải gửi lại toàn bộ.
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: 'gpt-3.5-turbo',
});
Hãy để ý đến messages là một mảng dữ liệu, nó có chia “role” cùng content đại diện cho tin nhắn. Chúng ta có 3 “role” là system, user, assistant đại diện cho tin nhắn hệ thống, tin nhắn của người dùng, và tin nhắn của ChatGPT. Tổ hợp các role này xen kẽ nhau tạo nên một ngữ cảnh cụ thể mà ChatGPT có thể dùng nó để phân tích và đưa ra câu trả lời chính xác.
Dựa vào đó, tôi cần truyền vào tất cả nội dung từ lúc bắt đầu hỏi và cả những câu trả lời của chính nó để nó hiểu được. Tôi tạo ra một biến messages là một mảng, mỗi khi hỏi hoặc nhận được phản hồi tôi sẽ push nội dung vào mảng và gửi trong lần tiếp theo. Cứ tưởng thế là xong xuôi rồi thì một lỗi khác lại xuất hiện: “This model's maximum context length is 4097 tokens”.
Tiếp tục lang thang, tôi được biết lỗi trên là do lượng ký tự gửi đến ChatGPT quá dài. Trong bài viết Tích hợp ChatGPT vào dịch bài viết trong AdminCP, tôi có nhắc đến khái niệm tokens trong OpenAI và đưa ra sự liên tưởng 1 token có thể coi tương đương với 1 từ thì điều này chưa chính xác cho lắm. Để ước tính được lượng token từ một chuỗi kí tự, bạn đọc có thể vào trang tokenizer - OpenAI để tự mình kiểm tra cho chính xác. Quay trở lại với vấn đề, vì là dịch bài viết với số lượng ký tự quá lớn cho nên lượng tokens cũng lớn và khiến cho ChatGPT từ chối xử lý.
Tôi tìm thấy nhiều lời khuyên rằng nên nhờ ChatGPT tóm tắt lại cuộc trò chuyện trước đó, rồi lưu trữ lại và gửi lên cho lần sau. Điều này đảm bảo được việc lưu trữ với dung lượng thấp mà nó vẫn có thể hiểu được một ít bối cảnh trước đó. Nhưng điều này có vẻ vô tác dụng với việc dịch, vì không thể tóm tắt rồi bảo nó dịch tiếp được. Tiếp tục là những lời khuyên nên chia nhỏ bài viết ra thành từng phần rồi dịch ít một, ít một. Hmm, thế thì có khá nhiều điều cần xử lý, nào là tính toán lượng tokens, chia bài viết thành các khối có ngữ nghĩa hoàn chỉnh để dịch được chính xác hơn… Nhưng nếu không còn cách nào khác thì phải làm thôi.
Tò mò, tôi nghiên cứu phương thức openai.chat.completions.create thì phát hiện ra thông số model chấp nhận một số model có kích thước đầu vào - ra lớn hơn như hình dưới đây:
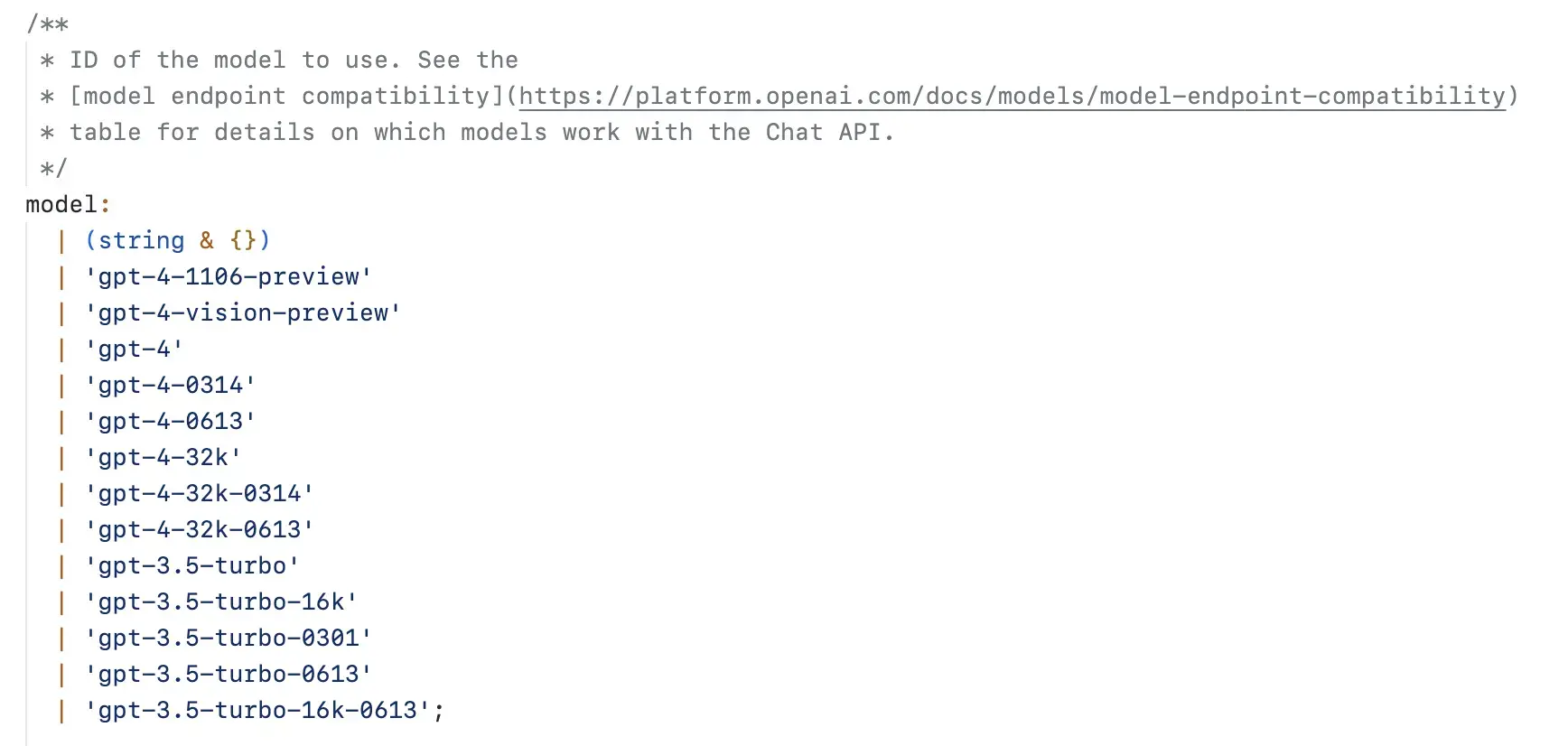
Do đó, khi tôi đổi model mặc định gpt-3.5-turbo sang gpt-3.5-turbo-16k thì thật tuyệt vời, mọi thứ đã hoạt động bình thường. Lúc này tôi hiểu, ngoài số context lớn giúp ChatGPT thông minh hơn nó còn có thể tiếp nhận được đầu vào và trả lời dài hơn, bù lại, giá tiền sẽ đắt hơn một chút xíu.
Mọi thứ hoạt động
Bấy giờ việc thiết lập ChatGPT qua API mới gần như hoàn thành. Nhưng bị một vấn đề đó là thời gian phản hồi khá lâu, trong lúc chờ đợi không biết là sẽ thành công hay thất bại, vì thế tôi truyền thêm options stream: true ở hàm create để nhận lại phản hồi stream, kết hợp với việc khởi tạo một máy chủ socket bằng thư viện socket.io sẽ giúp cho phản hồi giờ đây chuyển qua socket từng câu từng chữ, từ đó theo dõi được quá trình dịch đang diễn ra như thế nào.
const stream = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: 'Say this is a test' }],
stream: true,
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0]?.delta?.content || '');
}
Trong khi ChatGPT đang phản hồi mà tôi muốn bảo nó ngừng lại, mặc dù đã thử "kill" server đi rồi nhưng ngay sau đó gọi lại API create thì vẫn phải đợi một thời gian rất lâu sau đó mới nhận được phản hồi. Tôi đoán rằng việc tắt server không hoàn toàn yêu cầu ChatGPT ngừng trả lời câu hỏi trước đó. Do đó, phải chờ cho kết thúc thì yêu cầu tiếp theo mới được thực hiện. Điều này quá lãng phí vì OpenAI vẫn sẽ tính phí cho đầu ra mặc dù chúng ta không cần sử dụng phản hồi đó nữa.
Rất may, thư viện cung cấp thêm một hàm abort để yêu cầu ChatGPT dừng phản hồi. Bạn đọc có thể tham khảo tài liệu để biết cách triển khai hàm này để tránh lãng phí tokens sau này.